
You are currently browsing the tag archive for the ‘vapor mill’ tag.
The most widely cited study on the effect of cell phone usage on traffic accidents is this one by Redelmeier and Tibshirani in the New England Journal of Medicine. Their conclusion is that talking on the phone leads to a fourfold increase in accident risk.
Their method is interesting. It’s called a case crossover design, and it works like this. We want to know the odds ratio of an accident when you talk on the phone versus when you don’t. Let’s write it like this, where 


But we have no way of estimating numerator or denominator from traffic accident data because we would need to know the counterfactuals of how often people drive (with and without talking on the phone) and don’t have accidents. Case crossover studies are based on a little algebraic trick which transforms the odds ratio into something we can estimate, with just a little more data. Using Bayes’ rule and two lines of algebra, we can rewrite it like this.
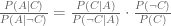
From accident data we can estimate the first term on the right-hand-side. We just calculate the fraction of accidents in which someone was talking on the phone. The finesse comes in when we estimate the second term. We don’t want to just estimate the overall frequency of cell phone use because we estimated the first term using a selected sample of people who had accidents. They may be different from the population as a whole. We want the cellphone usage rates for the people in our sample.
Case crossover studies take each person in the data who had an accident and ask them to report whether they were talking on the phone while driving at the same time of day one week before. Thus, each person generates their own control case. It’s a valid control because its the same person, driving at the same time, and on average therefore under the same conditions. These survey data are used to estimate the second term.
It’s really clever and its used a lot in epidemiological studies. (People get sick, some were exposed to some potential hazard, others not. The method is used to estimate the increase in risk of getting sick due to being exposed to the hazard.)
I have never seen it in economics however. In fact, this was the first I ever heard of it. So its natural to wonder why. And it doesn’t take long before you see that it has a serious weakness when applied to data with a lot of heterogeneity.
To see the problem, suppose that there are two types of people. The first group, in addition to being generally accident prone are also easily distracted. Everyone else is a safe driver and talking on cellphones doesn’t make them any less safe. Then our sample of people who actually had accidents would consist disproportionately of the first group. We would be estimating the effect of cell phone use on them alone. If they make up a small fraction of the population then we are drastically overestimating the increase in risk.
It’s fair to say that at best we can use the estimate of 4 as an upper bound on the risk ratio averaging over the entire population. That population average could be zero and still be consistent with the findings from case crossover studies. And there is no simple way to remedy the problems with this method. So I think there is good reason to approach this question from a different direction.
As I described before, if cell phone distractions increase accident risk we would see it by comparing the population of drivers to drivers with hearing impairment, who don’t use cell phones. And it turns out that the data exist. In the NHTSA’s database of traffic accidents, there is this variable:
P18 Person’s Physical Impairment
Definition: Identifies physical impairments for all drivers and non-motorists which may have contributed to the cause of the crash.
And “deaf” is impairment number 9.

They say you can’t compare the greats from yesteryear with the stars of today. But when it comes to Nobel laureates, to some extent you can.
The Nobel committee is just like a kid with a bag of candy. Every day (year) he has to decide which piece of candy to eat (to whom to give the prize) and each day some new candy might be added to his bag (new candidates come on the scene.) The twist is that each piece of candy has a random expiration date (economists randomly perish) so sometimes it is optimal to defer eating his favorite piece of candy in order to enjoy another which otherwise might go to waste.
The empirical question we are then left with is to uncover the Nobel committee’s underlying ranking of economists based on the awards actually given over time. It’s not so simple, but there are some clear inferences we can make. (Here’s a list of Laureates up to 2006, with their ages.)
To see that it is not so simple, note that just because X got the prize and Y didn’t doesn’t mean that X is better than Y. It could have been that the committee planned eventually to give the prize to Y but Y died earlier than expected (or Y is still alive and the time has not yet arrrived.)
When would the committee award the prize to X before Y despite ranking Y ahead of X? A necessary condition is that Y is older than X and is therefore going to expire sooner. (I am assuming here that age is a sufficient statistic for mortality risk.) That gives us our one clear inference:
If X received the prize before Y and X was born later than Y then X is revealed to be better than Y.
(The specific wording is to emphasize that it is calendar age that matters, not age at the time of receiving the prize. Also if Y never received the prize at all that counts too.)
Looking at the data, we can then infer some rankings.
One of the first economists to win the prize, Ragnar Frisch (who??) is not revealed preferred to anybody. By contrast, Paul Samuelson, who won the very next year is revealed preferred to kuznets, hicks, leontif, von hayk, myrdal, kantorovich, koopmans, friedman, meade, ohlin, lewis, schulz, stigler, stone, allais, haavelmo, coase and vickrey.
Outdoing Samuelson is Ken Arrow, who is revealed preferred to everyone Samuelson is plus simon, klein, tobin, debreu, buchanan, north, harsanyi, schelling and hurwicz (! hurwicz won the prize 37 years later!), but minus kuznets (a total of 25!)
Also very impressive is Robert Merton who had an incredible streak of being revealed preferred to everyone winning the prize from 1998 to 2006, ended only by Maskin and Myerson (but see below.)
On the flipside, there’s Tom Schelling who is revealed to be worse than 28 other Laureates. Leo Hurwicz is revealed to be worse than all of those plus Phelps. Hurwicz is not revealed preferred to anybody, a distinction he shares with Vickrey, Havelmo, Schultz (who??), Myrdal (?), Kuznets and Frisch.
Paul Krugman is batting 1,000 having been revealed preferred to all (two) candidates coming after him: Williamson and Ostrom.
Similar exercises could be carried out with any prize that has a “lifetime achievement” flavor (for example Sophia Loren is revealed preferred to Sidney Poitier, natch.)
There’s a real research program here which should send decision theorists racing to their whiteboards. We deduced one revealed preference implication. Question: is that all we can deduce or are there other implied relations? This is actually a family of questions that depend on how strong assumptions we want to make about the expiration dates in the candy bag. At one extreme we could ask “is any ranking consistent with the boldface rule above rationalizable by some expiration dates known to the child but not to us?” My conjecture is yes, i.e. that the boldface rule exhausts all we can infer.
At the other end, we might assume that the committee knows only the age of the candidates and assumes that everyone of a given age has the average mortality rate for that age (in the United States or Europe.) This potentially makes it harder to rationalize arbitrary choices and could lead to more inferences. This appears to be a tricky question (the infinite horizon introduces some subtleties. Surely though Ken Arrow has already solved it but is too modest to publish it.)
Of course, the committee might have figured out that we are making inferences like this and then would leverage those to send stronger signals. For example, giving the prize to Krugman at age 56 becomes a very strong signal. This would add some noise.
Finally, the kid-with-a-candy-bag analogy breaks down when we notice that the committee forms bundles. Individual rankings can still be inferred but more considerations come into play. Maskin and Myerson got the prize very young, but Hurwicz, with whom they shared the prize, was very close to expiration. We can say that the oldest in a bundle is revealed preferred to anyone older who receives a prize later. Plus we can infer rankings of fields by looking at the timing of prizes awarded to researchers in similar areas. For example, time-series econometrics (2003) is revealed preferred to the theory of organizations (2009.)
The Bottom Line: There is clear advice here for those hoping to win the prize this year, and those who actually do. If you do win the prize, for your acceptance speech you should start by doing pushups to prove how virile you are. This signals to the world that you were not given the award because of an impending expiration date but that in fact there was still plenty of time left but the committee still saw fit to act now. And if you fear you will never win the prize, the sooner you expire the more willing will the public be to believe that you would have won if only you had stuck around.
Cell phone use increases the risk of traffic accidents right? But how do we prove that? By showing that a large fraction of accidents involve people talking on cell phones? Not enough. A huge fraction of accidents involve people wearing shoes too.
I thought about this for a while and short of a careful randomized experiment it seems hard to get a handle on this using field data. I poked around a bit and I didn’t find much that looked very convincing. To give you an example of the standards of research on this topic, one study I found actually contains the following line:
Results Driver’s use of a mobile phone up to 10 minutes before a crash was associated with a fourfold increased likelihood of crashing (odds ratio 4.1, 95% confidence interval 2.2 to 7.7, P < 0.001).
(Think about that for a second.)
Here’s something we could try. Compare the time trend of accident rates for the overall population of drivers with the same trend restricted to deaf drivers. We would want a time period that begins before the widespread use of mobile phones and continues until today. Presumably the deaf do not talk on cell phones. So if cell phone use contributed to an increase in traffic risk we would see that in the general population but not among the deaf.
On the other hand, the deaf can use text messaging. Since there was a period of time when cell phones were in widespread use but text messaging was not, then this gives us an additional test. If text messaging causes accidents, then this is a bump we should see in both samples.
Anyone know if the data are available? I am serious.
The data on first vs. second serve win frequency cannot be taken at face value because of selection problems that bias against second serves. The general idea is that first serves always happen but second serves happen only when first serves miss. The fact that the first serve missed is information that at this moment serving is harder than usual. In practice this can be true for a number of reasons: windy conditions, it is late in the match, or the server is just having a bad streak. In light of this, we can’t conclude from the raw data that professional tennis players are using sub-optimal strategy on second serves.
To get a better comparison we need an identification strategy: some random condition that determines whether the next serve will be a first or second serve. We would restrict our data set to those random selections. Sounds hopeless?
When a first serve hits the net and goes in it is a “let” and the next serve is again a first serve. But if it goes out then it is a fault. The impact with the net introduces the desired randomness, especially when the ball hits the tape and bounces up. Conditional on hitting the tape, whether it lands in or out can be considered statistically independent of the server’s current mental state, the wind conditions, and the stage of the game. These are the ingredients for a “natural experiment.”
Here is a theory of why placebos work. I don’t claim that it is original, it seems natural enough that I am surely not the first to suggest it. But I don’t think I have heard it before.
Getting better requires an investment by the body, by the immune system say. The investment is costly: it diverts resources in the body, and it is risky: it can succeed or fail. But the investment is complementary with externally induced conditions, i.e. medicine. Meaning that the probability of success is higher when the medicine is present.
Now the body has evolved to have a sense of when the risk is worth the cost, and only then does it undertake the investment. Being sick means either that the investment was tried and it failed or that the body decided it wasn’t worth taking the risk (yet! the body has evolved to understand option value.)
Giving a placebo tricks the body into thinking that conditions have changed such that the investment is now worth it. This is of course bad in that conditions have not changed and the body is tricked into taking an unfavorable gamble. Still, the gamble succeeds with positive probability (just too low a probability for it to be profitable on average) and in that case the patient gets better due to the placebo effect.
The empirical implication is that patients who receive placebos do get better with positive probability, but they also get worse with positive probability and they are worse off on average than patients who received no treatment at all (didn’t see any doctor, weren’t part of the study.) I don’t know if these types of controls are present in typical trials.
Sarcasm is a way of being nasty without leaving a paper trail.
If I say “No dear, of course I don’t mind waiting for you, in fact, sitting out here with the engine running is exactly how I planned to spend this whole afternoon” then the literal meaning of my words leaves me completely blameless despite their clearly understood venom.
This convention had to evolve. If it didn’t already exist it would be invented. A world without sarcasm would be out of equilibrium.
Because if sarcasm did not exist then I have the following arbitrage opportunity: I can have a private vindictive chuckle by giving my wife that nasty retort without her knowing I was being nasty. The dramatic irony of that is an added bonus.
That explains the invention of sarcasm. But it evolves from there. Once sarcasm comes into existence then the listener learns to recognize it. This blunts the effect but doesn’t remove it altogether. Because unless its someone who knows you very well, the listener may know that you are being sarcastic but it will not be common knowledge. She feels a little less embarrassment about the insult if there is a chance that you don’t know that she knows that you are insulting her, or if there was some higher-order uncertainty. If instead you had used plain language then the insult would be self-evident.
And even when its your spouse and she is very accustomed to your use of sarcasm, the convention still serves a purpose. Now you start to use the tone of your voice to add color to the sarcasm. You can say it in a way that actually softens the insult. “Dinner was delicious.” A smile helps.
But you can make it even more nasty too. Because once it becomes common knowledge that you are being sarcastic, the effect is like a piledriver. She is lifted for the briefest of moments by the literal words and then it’s an even bigger drop from there when she detects the sarcasm and knows that you know that she knows …. that you intentionally set the piledriver in motion.
 is liftin' me higher...")
Sarcasm could be modeled using the tools of psychological game theory.
I wrote previously about the equilibrium effects of avoiding spoilers. You might want to strategically generate spoilers to counteract these effects. I just discovered that a website exists for generating spoilers: shouldiwatch.com.
The premise is that you have recorded a sporting event on your DVR and you want to enjoy watching it. Enjoyment has something to do with the resolution of uncertainty. So you have preferences for the time path of uncertainty resolution. Maybe you want your good news in lumps and your bad news revealed gradually. Maybe you like suspense. A mechanism can fine tune and enhance these.
But it always cuts two ways. A spoiler creates a discrete jump in your beliefs at the beginning followed by another effect on your beliefs as the game unfolds. For example, ShouldIWatch.com allows me to set a program that will warn me when the Lakers beat the Celtics by more than 10 points. The idea is that I don’t want to watch a blowout. But there is an effect on my beliefs: knowing that it is not a blowout changes my expectations at the beginning of the game. Then there is a second effect during the game: if the Lakers take a 15 point lead, I am expecting a come-back by the Celtics. In return for the increased excitement at the beginning I pay with reduced excitement in the interim.
This trade-off could make for a cool model. An event will unfold over time. An observer cares about the outcome and cares about the path of his beliefs but will watch the event after it is over. A mechanism is a program which knows the full path of the event and reveals information to the observer before and while he watches the event. Design the mechanism which maximizes the observer’s overall expected value taking into account this tradeoff.
File this under psychological mechanism design.
Academics appreciate the pure search for knowledge, whether or not it can ever be put to use. This is the pinnacle:
In what appears to be an attempt on Amruthavalli’s part to understand suicide by hanging, the housewife hanged herself from the ceiling of her family home in Madivala on July 7.
What the suicide note says:
‘No one is responsible for my death. For many days I have harboured a wish and have had doubts about how people hang themselves. So just I am trying to get to the bottom of the matter by hanging myself. No one should be held responsible for my death. I love you Bava, I love you dad, mom and my sisters. I love you Saran. Thanks for everything Athama.’
-Amruthavalli
Hood hello: nimbupani.
Here is the advice from Annie Duke, professional poker player and the 2006 Champion of the World Series of Rock, Scissors, Paper:
The other little small piece of advice that I would give you is that people tend to throw rock on their first throw. Throwing paper is usually not a good strategy because they might throw scissors. You should throw rock as well.
The key is, and this is the best piece of advice that I can give you, if you do think that you recognize the pattern from your opponent, it’s good to try to throw a tie as opposed to a win. A tie will very often get you a tie or a win, whereas a win will get you a win or a loss. For example, if you think that someone might throw a rock, it’s good to throw rock back at them. You should be going for ties.
If at first it sounds dumb, think again. The idea is some combination of pattern learning and level-k thinking: If she thinks that I think that I have figured out her pattern and it dictates that she will play Rock next, then she expects me to play Paper and so in fact she will play Scissors. That means I should play Rock because either I have correctly guessed her pattern and she will indeed play Rock and I will tie, or she has guessed that I have guessed her pattern and she will play Scissors and I will win.
She is essentially saying that players are good at recognizing patterns and that most players are at most level 2
Research note: why are we wasting time analyzing penalty kicks? Can we get data on competitive RoShamBo? While we wait for that here is an exercise for the reader: find the minimax strategy in this game:
As my wife will tell you, I hate clutter. Stuff that’s lying around I either put to use or throw away. Stray thoughts get the treatment today.
- Have the wasps in my neighborhood learned that the smell of citronella is actually a surefire signal that there’s something good nearby?
- I thank mother Earth for her two hemispheres as I enjoy this persimmon from Chile.
- Can the drunks’ favorite poker game, Indian, be solved like the dirty faces or other those common-knowledge puzzles?
- Classical field theory is doing physics by revealed preference.
- The reason it is so boring watching the Williams’ sisters in a grand slam final is that you either like both or hate both. Either way there’s nothing to root for.
- Is it pure coincidence that the Risk, Uncertainty and Decision Conference is on the exact same day as the Behavioral Economics Summer School two years in a row?
- Johnny Rotten is the perfection of Bob Dylan’s vocal style.
- How well do prediction markets forecast American Idol winners? Completely decentralized information, short time-horizon, shouldn’t this be an ideal test case?

I blogged about this before and in honor of the start of the French Open I gave it some thought again and here are two ideas.
Deuce. Each game is a race to 4 points. (And if you are British 4 = 50.) But you have to win by 2. Conditional on reaching a 3-3 game, the deuce scoring system helps the stronger player by comparison to a flat race to 4. In fact, if being a stronger player means you have a higher probability of winning each point then any scoring system in which you have to win by n is better for the stonger player than the system where you only have to win by n-1.
You can think about a random walk, starting at zero (deuce) with a larger probability of moving up than down, and consider the event that it reaches n or -n. The relative likelihood of hitting n before -n is increasing in n.
This is confounded by the fact that the server has an advantage even if he is the weaker player. But it will average out across service-games.
Grouping scoring into games and sets. Suppose that being a stronger player means that you are better at winning the crucial points. Then grouped scoring makes it clear which are the crucial points. To take an extreme example, suppose that the stronger player has one freebie: in any match he can pick one point and win that point for sure.
In a flat (ungrouped) scoring system, all points are equal and it doesn’t matter where you spend the freebie. And it doesn’t change your chance of winning by very much. But in grouped scoring you can use your freebie at game- or set-point. And this has a big impact on your winning probability.
Conjecture: freebies will be optimally used when you are game- or set-point down, not when it is set-point in your favor. My reasoning is that if you save your freebie when you have set-point, you will still win the set with high probability (especially because of deuce.) If you switch to using it when you are set-point down, its going to make a difference in the cases when there is a reversal. Since you are the stronger player and you win each point with higher probability, the reversals in your favor have higher probability.
Any thoughts on the conjecture? It should have implications for data. The stronger players do better when they are ad-down then when they have the ad. And across matches, their superiority over weaker players is exaggerated in the ad-down points.
My French Open forecast: This could be the year when we have a really interesting Federer-Nadal final.
If doctors were to fine tune their prescriptions to take maximal advantage of the placebo effect, what would they do? It’s hard to answer this question even with existing data on the strength of the placebo effect because beliefs, presumably the key to the placebo effect, would adjust if placebo prescription were widespread.
Indeed, over the weekend I saw a paper presented by Emir Kamenica which strongly suggests that equilibrium beliefs matter for placebos. In an experiment on the effectiveness of anti-histamines, some subjects were shown drug ads at the same time they took the drug. The ads had an impact on the effectiveness of the drug but only for subjects with less prior experience with the same drug. The suggestion is that those with prior experience have already reached their equilibrium placebo effect. (It appears that the paper is not yet available for download.)
So we need a model of the placebo effect in equilibrium. Suppose that patients get a placebo a fraction 
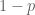



This equilibrium condition implicitly defines a function
The benefit of the model is that it allows us to notice something that may not have been obvious before. If instead of using placebos by varying 

as the equilibrium condition which defines effectiveness 
The something to notice is that, if the function 


Now this is just a statement about the feasible set. The benefit of placebo may come from the ability to implement the same outcome but with lower cost. In terms of the model this would occur if the 

Here is a wide-ranging article about proposals to utilize placebos as medicine.
But according to advocates, there’s enough data for doctors to start thinking of the placebo effect not as the opposite of medicine, but as a tool they can use in an evidence-based, conscientious manner. Broadly speaking, it seems sensible to make every effort to enlist the body’s own ability to heal itself–which is what, at bottom, placebos seem to do. And as researchers examine it more closely, the placebo is having another effect as well: it is revealing a great deal about the subtle and unexpected influences that medical care, as opposed to the medicine itself, has on patients.
The article never mentions it so I wonder if any consideration has been given to the equilibrium effects. Presumably the placebo effect requires the patient to believe that the drug is real. Then widespread use of true placebos will dilute the placebo effect. Since real drugs also contribute a placebo effect on top of any pharmacological effects, the placebo component of existing drugs will be reduced.
Does the benefit of using placebos outweigh the cost of reducing the effectiveness of non-placebos? If there is a complementarity between the placebo effect and real pharmacological effects it could be that zero is the optimal ratio of placebo to non-placebo treatments.
Note to my behavioral economics class: this is a good example of a topic that would require the tools of psychological game theory due to the direct payoff consequences of beliefs.
I’ve been thinking about the Sleeping Beauty problem a lot and I have come up with a few variations that help with intuition. So far I don’t see any clear normative argument why your belief should be anything in particular (although some beliefs are obviously wrong.) My original argument was circular because I wanted to prove that your willingness to be reveals that you assign equal probability but I essentially assumed you assigned equal probability in calculating the payoffs to those bets.
Nevertheless the argument does show that the belief of 1/2 is a consistent belief in that it leads to betting behavior with a resulting expected payoff which is correct. On the other hand a belief of 1/3 is not consistent. If, upon waking, you assign probability 1/3 to Heads you will bet on Tails and you will expect your payoff to be (2/3)2 – (1/3)1 = $1. But your true expected payoff from betting tails is 50 cents. This means that you are vulnerable to the following scheme. At the end of their speech, the researchers add “In order to participate in this bet you must agree to pay us 75 cents. You will pay us at the end of the experiment, and only once. But you must decide now, and if you reject the deal in any of the times we wake you up, the bet is off and you pay and receive nothing.”
If your belief is 1/3 you will agree to pay 75 cents because you will expect that your net payoff will be $1 – 75 cents = 25 cents. But by agreeing the deal you are actually giving yourself an expected loss of 25 cents (50 cents – 75 cents.) If your belief is 1/2 you are not vulnerable to these Dutch books.
Here are the variations.
- (Clones in their jammies) The speech given by the researchers is changed to the following. “We tossed a fair coin to decide whether we would clone you, and then wake up both instances of you. The clone would share all of your memories, and indeed you may be that clone. Tails: clone, Heads: no clone (but still we would wake you and give you this speech and offer.) You (and your clone if Tails) can bet on the coin. In the event of tails, your payoff will be the sum of the payoffs from you and your clone’s bet (and the same for you if you are the clone.)”
- (Changing the odds) Suppose that the stakes in the event of Heads is $1.10. Now those with belief 1/2 strictly prefer to bet Heads (in the original example they were indifferent.) And this gives them an expected loss, whereas the strategy of betting Tails every time would still give an expected gain. This exaggerates the weirdness but it is not a proof that 1/2 is the wrong belief. The same argument could be applied to the clones where we would have something akin to a Prisoner’s dilemma. It is not an unfamiliar situation to have an individual incentive to do something that is bad for the pair.
- Suppose that the coin is not fair, and the probability of Tails is 1/n. But in the event of Tails you will be awakened n times. The simple counting exercise that leads to the 1/3 belief seemed to rely on the fair coin in order to treat each awakening equal. Now how do you do it?
- The experimenters give you the same speech as before but add this: “each time we wake you, you will place your bet BUT in the event of Tails, at your second awakening, we will ignore your choice and substitute a bet on Tails on your behalf.” Now your bet only matters in the first awakening. How would you bet now? (“Thirders” who are doing simple counting would probably say that, conditional on the first awakening, the probability of Heads is 1/2. Is it?)
- Same as 4 but the bet is substituted on the first awakening in the event of Tails. Now your bet only matters if the coin came up Heads or it came up Tails and this is the second awakening. Does it make any difference?
Via Robert Wiblin here is a fun probability puzzle:
The Sleeping Beauty problem: Some researchers are going to put you to sleep. During the two days that your sleep will last, they will briefly wake you up either once or twice, depending on the toss of a fair coin (Heads: once; Tails: twice). After each waking, they will put you to back to sleep with a drug that makes you forget that waking.
The puzzle: when you are awakened, what probability do you assign to the coin coming up heads? Robert discusses two possible answers:
First answer: 1/2, of course! Initially you were certain that the coin was fair, and so initially your credence in the coin’s landing Heads was 1/2. Upon being awakened, you receive no new information (you knew all along that you would be awakened). So your credence in the coin’s landing Heads ought to remain 1/2.
Second answer: 1/3, of course! Imagine the experiment repeated many times. Then in the long run, about 1/3 of the wakings would be Heads-wakings — wakings that happen on trials in which the coin lands Heads. So on any particular waking, you should have credence 1/3 that that waking is a Heads-waking, and hence have credence 1/3 in the coin’s landing Heads on that trial. This consideration remains in force in the present circumstance, in which the experiment is performed just once.
Let’s approach the problem from the decision-theoretic point of view: the probability is revealed by your willingness to bet. (Indeed, when talking about subjective probability as we are here, this is pretty much the only way to define it.) So let me describe the problem in slightly more detail. The researchers, upon waking you up give you the following speech.
The moment you fell asleep I tossed a fair coin to determine how many times I would wake you up. If it came up heads I would wake you up once and if it came up tails I would wake you up twice. In either case, every time I wake you up I will tell you exactly what I am telling you right now, including offering you the bet which I will describe next. Finally, I have given you a special sleeping potion that will erase your memory of this and any previous time I have awakened you. Here is the bet: I am offering even odds on the coin that I tossed. The stakes are $1 and you can take either side of the bet. Which would you like? Your choice as well as the outcome of the coin are being recorded by a trustworthy third party so you can trust that the bet will be faithfully executed.
Which bet do you prefer? In other words, conditional on having been awakened, which is more likely, heads or tails? You might want to think about this for a bit first, so I will put the rest below the fold.
People seem to care not just about their own material success but how it measures up to their peers. There is probably a good evolutionary reason for this. Larry Samuelson has shown one way to formalize this idea in this paper.
But here’s a different story and one that is extremely simple. Imagine a speed skating competition with 10 competitors. Suppose that 8 of them skate their heats solo with no knowledge of the others’ times. The remaining 2 also have no knowledge of the others’ times except that they race simultaneously side by side.
Other things equal, each of the two parallel skaters has a greater than 1/10 chance of winning.
Does game theory have predictive power? The place to start if you want to examine this question is the theory of zero sum games where the predictions are robust: you play the minimax strategy: the one that maximizes your worst-case payoff. (This is also the unique Nash equilibrium prediction.)
The theory has some striking and counterintuitive implications. Here’s one. Take the game rock-scissors-paper. The loser pays $1 to the winner. As you would expect, the theory says each should play each strategy with 1/3 probability. This ensures that each player is indifferent among all three strategies.
Now, for the counterintuitive part, suppose that an outsider will give you an extra 50 cents if you play rock (not a zero-sum game anymore but bear with me for a minute), regardless of the other guy’s choice. What happens now? You are no longer indifferent among your three strategies, so your opponent’s behavior must change. He must now play paper with higher probability in order to reduce your incentive to play rock and restore your indifference. Your behavior is unchanged.
Things are even weirder if we change both players’ payoffs at the same time. Take the game matching pennies. You and your opponent hold a penny and secretly place it with either heads or tails facing up. If the pennies match you get $1 from your opponent. If they don’t match you pay $1.
Suppose we change the payoffs so that now you receive $2 from your opponent if you match heads-heads. All other outcomes are the same as before. (The game is still zero-sum) What happens? Like with RSP, your opponent must play heads less often in order to reduce your incentive to play heads. But since your opponent’s payoffs have also changed, your behavior must change too. In fact you must play heads with lower probability, because the payoffs have now made him prefer tails to heads.
How can we examine this prediction in the field? There is a big problem because usually we only observe outcomes and not the players’ payoffs which might vary day-to-day depending on conditions only known to them. To see what I mean, consider the game-within-a-game between a pitcher and a runner on first base in baseball. The runner wants to steal second, the pitcher wants to stop him. The pitcher decides whether to try a pick-off or pitch to the batter. The runner decides whether to try and steal.
When he runs and the pitcher throws to the plate, the chance that he beats the throw from the catcher depends on how fast he is and how good the catcher is, and other details. Thus, the payoff to the strategy choices (steal, pitch) is something we cannot observe. We just see whether he steals succesfully.
But there is still a testable prediction, even without knowing anything about these payoffs. By direct analogy to matching pennies, a faster runner will try to steal less often than a slower runner. And the pitcher will more often try to pick off the faster runner at first base. Therefore, in the data there will be correlation between the pitcher’s behavior and the runner’s. If the pitcher is throwing to first more frequently, that is correlated with a faster runner which in turn predicts that the runner tries to steal less often.
This correlation across players (in aggregate data) is a prediction that I believe has never been tested. (It’s strange to think of non-cooperative play of a zero-sum game as generating correlation across players.) And while many studies have failed to reject some basic implications of zero-sum game theory, I would be very surprised if this prediction were not soundly rejected in the data.
(The pitcher-runner game may not be the ideal place to do this test, can anyone think of another good, binary zero-sum game where there is good data?)
We tend to think of intellectual property law as targeted mostly at big ideas with big market value. But for every big idea there are zillions of little ideas whose value adds up to more. Little ideas are little because they are either self-contained and make marginal contributions or they are small steppingstones, to be combined with other little ideas, which eventually are worth a lot.
It’s now cheap to spread little ideas. Whereas before even very small communication costs made most of them prohibitively expensive to share. In some cases this is good, but in some cases it can be bad.
When it comes to the nuts and bolts kinds of ideas, like say how to use perl to collect data on the most popular twitter clients, ease of dissemination is good and intellectual property is bad. IP protection would mean that the suppliers of these ideas would withold lots of them in order to profit from the remainder. Without IP protection there is no economic incentive to keep them to yourself and the infinitessimal cost of sharing them is swamped by even the tiniest pride/warm glow motives.
Now the usual argument in favor of IP protection is that it provides an economic incentive for generating these ideas. But we are talking about ideas that don’t come from research in the active sense of that word. They are the byproduct of doing work. When its cheap to share these ideas, IP protection gets in the way.
The exact same argument applies to many medium-sized ideas as well. And music.
But there are ideas that are pure ideas. They have no value whatsoever except as ideas. For example, a story. Or basic research. The value of a pure idea is that it can change minds. Ideas are most effective at changing minds when they arrive with a splash and generate coordinated attention. If some semblance of the idea existed in print already, then even a very good elaboration will not make a splash. “That’s been said/done before.”
Its too easy now to spread 1/nth-baked little ideas. Before, when communication costs were high it took investment in polishing and marketing to bring the idea to light. So ideas arrived slowly enough for coordinated attention, and big enough to attract it. Now, there will soon be no new ideas.
Blogs will interfere with basic research, especially in the social sciences.
When it comes to ideas, here’s one way to think about IP and incentives to innovate. It’s true that any single individual needs extra incentive to spend his time actively trying to figure something out. That’s hard and it takes time. But, given the number of people in the world, 99.999% of the ideas that would be generated by active research would almost certainly just passively occur to at least one individual.
Or more generally, does your initial job placement matter for your long-term success? Or does “bad luck” on the job market eventually wash out? A 2006 paper from Paul Oyer looks at this question.
In this paper, I show that initial career placement matters a great deal in determining the careers of economists. Each place higher in rank of initial insti-tution causes an economist to work at an institution ranked 0.6 places higher in the time period from three to 15 years later. Also, the fact that an economist originally gets a job at a top-50 institution makes that economist 60 percent more likely to work at a top-50 school later in his or her career. While it would obviously come as no surprise to find that economists at higher-ranked schools have higher research output, I will present evidence that for a given economist—that is, holding innate ability constant— obtaining an initial placement at a higher-ranked institution leads to greater professional productivity.
He circumvents the obvious endogeneity issue: there may be some measure of your quality that can’t be observed in the data and then lower initial placement is going to be correlated with lower intrinsic quality. The way he gets around this is to compare cohorts in strong-market years with cohorts from weaker years. Suppose that the business cycle is uncorrelated with your intrinsic skill and bad times means worse than usual placement. Then the same quality worker will have worse placement in weak-market years.
In fact, Oyer finds that students who enter the market in weak years are less successful even in the long run. This is evidence that their initial placement mattered.
There remain some selection problems, however. For example, students have choice over which year to enter the market. It could be that, anticipating the worse placements, the best students enter the market a year before a downturn or wait a year after. Also, in bad years the best students might find altogether better alternatives than academia and go to the private sector.
Here’s my idea for a different instrument: couples. It often happens that a student on the market has a spouse who is seeking a job in the private sector. Finding a good job in the same city for both partners is more constraining than a solo search and typically the student will have to compromise, taking their seond- or third-best offer.
If being married at the time of entering the market is uncorrelated with your unobservable talent as an economist, then a difference in the long-run success of PhDs with dual searches would be evidence of the effect of initial placement.
(I would focus on academic-private sector couples. In an academic-academic couple, the two quite often market themselves as a bundle to the same institution and the worse of the two gets a better placement than he would if he were solo. But it would be interesting to compare academic-academics to academic-private.)
(Casquette cast: Seema Jayachandran)
Its obvious right? Ok but before you read on, say the answer to yourself.

Is it because he is the most able to make up any lost time by the earlier teammates? Because in the anchor leg you know exactly what needs to be done? Now what about this argument: The total time is just the sum of the individual times. So it doesn’t matter what order they swim in.
That would be true if everyone was swimming (running, potato-sacking, etc.) as fast as they could. But it is universally accepted strategy to put the fastest last. If you advocate this strategy you are assuming that not everyone is swimming as fast as they can.
For example, take the argument that in the anchor leg you know exactly what needs to be done. Inherent in this argument is the view that swimmers swim just fast enough to get the job done.
(That tends to sound wrong because we don’t think of competitive athletes as shirkers. But don’t get drawn in by the framing. If you like, say it this way: when the competition demands it, they “rise to the occasion.” Whichever way you say it, they put in more or less effort depending on the competition. And one does not have to interpret this as a cold calculation trading off performance versus effort. Call it race psychology, competitive spirit, whatever. It amounts to the same thing: you swim faster when you need to and therefore slower when you don’t.)
But even so its not obvious why this by itself is an argument for putting the fastest last. So let’s think it through. Suppose the relay has two legs. The guy who goes first knows how much of an advantage the opposing team has in the anchor leg and therefore doesn’t he know the amount by which he has to beat the opponent in the opening leg?
No, for two reasons. First, at best he can know the average gap he needs to finish with. But the anchor leg opponent might have an unusually good swim (or the anchor teammate might have a bad one.) Without knowing how that will turn out, the opening leg swimmer trades off additional effort in return for winning against better and better (correspondingly less and less likely) possible performance by the anchor opponent. He correctly discounts the unlikely event that the anchor opponent has a very good race, but if he knew that was going to happen he would swim faster.
The anchor swimmer gets to see when that happens. So the anchor swimmer knows when to swim faster. (Again this would be irrelevant if they were always swimming at top speed.)
The other reason is similar. You can’t see behind you (or at least your rear-ward view is severely limited.) The opening leg swimmer can only know that he is ahead of his opponent, but not by how much. If his goal is to beat the opening leg opponent by a certain distance, he can only hope to do this on average. He would like to swim faster when the opening leg opponent is behind but doing better than average. The anchor swimmer sees the gap when he takes over. Again he has more information.
There is still one step missing in the argument. Why is it the fastest swimmer who makes best use of the information? Because he can swim faster right? It’s not that simple and indeed we need an assumption about what is implied by being “the fastest.” Consider a couple more examples.
Suppose the team consists of one swimmer who has only one speed and it is very fast and another swimmer who has two speeds, both slower than his teammate. In this case you want the slower swimmer to swim with more information. Because in this case the faster swimmer can make no use of it.
For another example, suppose that the two teammates have the same two speeds but the first teammate finds it takes less effort to jump into the higher gear. Then here again you want the second swimmer to anchor. But this time it is because he gets the greater incentive boost. You just tell the first swimmer to swim at top speed and you rely on the “spirit of competition” to kick the second swimmer into high gear when he’s behind.
More generally, in order for it to be optimal to put the fastest swimmer in the anchor leg it must be that faster also means a greater range of speeds and correspondingly more effort to reach the upper end of that range. The anchor swimmer should be the team’s top under-achiever.
Exercises:
- What happens in a running-backwards relay race? Or a backstroke relay (which I don’t think exists.)
- In a swimming relay with 4 teammates why is it conventional strategy to put the slowest swimmer third?
In the top tennis tournaments there is a limited instant-replay system. When a player disagrees with a call (or non-call) made by a linesman, he can request an instant-replay review. The system is limited because the players begin with a fixed number of challenges and every incorrect challenge deducts one from that number. As a result there is a lot of strategy involved in deciding when to make a challenge.
Alongside the challenge system is a vestige of the old review system where the chair umpire can unilaterally over-rule a call made by the linesman. These over-rules must come immediately and so they always precede the players’ decision whether to challenge, and this adds to the strategic element.
Suppose that A’s shot lands close to B’s baseline, the ball is called in by the linesman but this call is over-ruled by the chair umpire. In these scenarios, in practice, it is almost automatic that A will challenge the over-ruled call. That is, A asks for an instant-replay hoping it will show that the ball was indeed in.
This seems logical. It looked in to the linesman and that is good information that it was actually in. For example, compare this scenario to the one in which the ball was called out by the linesman and that call was not over-ruled. In that alternative scenario, one party sees the the ball out and no party is claiming to see the ball in. In the scenario with the over-rule, there are two opposing views. This would seem to make it more likely that the ball was indeed in.
But this is a mistake. The chair umpire knows when he makes the over-rule that the linesman saw it in. He factors that information in when deciding whether to over-rule. His willingness to over-rule shows that his information is especially strong: strong enough to over-ride an opposing view. And this is further reinforced by the challenge system because the umpire looks very bad if he over-rules and a challenge shows he is wrong.
I am willing to bet that the data would show challenges of over-ruled calls are far less likely to be successful than the average challenge.
A separate observation. The challenge system is only in place on the show courts. Most matches are played on courts that are not equipped for it. I would bet that we could see statistically how the challenge system distorts calls by the linesmen and over-rules by the chair umpire by comparing calls on and off the show courts.
Here’s a purely self-interested rationale for affirmative action in hiring. An organization repeatedly considers candidates for employment. A candidate is either good or just average and there are minority and non-minority candidates. The quality of the candidate and his race are observable. The current members decide collectively whether to make a job offer to the candidate.
What’s not observable is whether the applicant is biased against the other race. A biased member prefers not to belong to an organization with members of the other race. In particular, if hired, he will tend to vote against hiring them.
Unbiased non-minority members of such an organization will optimally hold minority applicants to a lower quality standard, at least initially. The reason is simple. An organization with no minority members will have their job offers more often accepted by biased non-minority candidates who will then make it harder to hire high quality minority candidates in the future. Since bias is not observable, affirmative action is an alternative instrument to ensure that the organization is not hospitable to those who are biased.
The effect is weaker in the opposite direction. Even if there are minority applicants who are biased in favor of minorities, their effect on the organization’s decision-making will be smaller because they are in the minority. So at the margin there is a gain to practicing at least some affirmative action.
(This also explains why every economics department should have at least one structural and one reduced-form empirical economist.)
Via The Volokh Conspiracy, I enjoyed this discussion of the NFL instant replay system. A call made on the field can only be overturned if the replay reveals conclusive evidence that the call was in error. Legal scholarship has debated the merits of such a system of appeals relative to the alternative of de novo review: the appelate body considers the case anew and is not bound by the decision below.
If standards of review are essentially a way of allocating decisionmaking authority between trial and appellate courts based on their relative strengths, then it probably makes sense that the former get primary control over factfinding and trial management (i.e., their decisions on those matters are subject only to clear error or abuse of discretion review), while the latter get a fresh crack at purely “legal” issues (i.e., such issues are reviewed de novo). Heightened standards of review apply in areas where trial courts are in the best place to make correct decisions.
These arguments don’t seem to apply to instant replay review. The replay presumably is a better document of the facts than the realtime view of the referee. But not always. Perhaps the argument against in favor of deference to the field judge is that it allows the final verdict to depend on the additional evidence from the replay only when the replay angle is better than that of the referee.
That argument works only if we hold constant the judgment of the referee on the field. The problem is that the deferential system alters his incentives due to the general principle that it is impossible to prove a negative. For example consider the (reviewable) call of whether a player’s knee was down due to contact from an opposing player. Instant replay can prove that the knee was down but it cannot prove the negative that the knee was not down. (There will be some moments when the view is obscured, we cannot be sure that the angle was right, etc.)
Suppose the referee on the field is not sure and thinks that with 50% probability the knee was down. Consider what happens if he calls the runner down by contact. Because it is impossible to prove the negative, the call will almost surely not be overturned and so with 100% probability the verdict will be that he was down (even though that is true with only 50% probability.)
Consider instead what happens if the referee does not blow the whistle and allows the play to proceed. If the call is challenged and the knee was in fact down, then the replay will very likely reveal that. If not, not. The final verdict will be highly correlated with the truth.
So the deferential system means that a field referee who wants the right decision made will strictly prefer a non-call when he is unsure. More generally this means that his threshold for making a definitive call is higher than what it would be in the absence of replay. This probably could be verified with data.
On the other hand, de novo review means that, conditional on review, the call made on the field has no bearing. This means that the referee will always make his decision under the assumption that his decision will be the one enforced. That would ensure he has exactly the right incentives.
A simple implication of sexual selection is that there should be a correlation between features that attract us sexually and characteristics that make our offspring more fit. Here is an article that studies the link between physical attraction and success in sport.
The better an American football player, the more attractive he is, concludes a team led by Justin Park at the University of Bristol, UK. Park’s team had women rate the attractiveness of National Football League (NFL) quarterbacks: all were elite players, but the best were rated as more desirable.
Meanwhile, a survey of more than a thousand New Scientist Twitter followers reveals a similar trend for professional men’s tennis players.
Neither Park nor New Scientist argue that good looks promote good play. Rather, the same genetic variations could influence both traits.
“Athletic prowess may be a sexually selected trait that signals genetic quality,” Park says. So the same genetic factors that contribute to a handsome mug may also offer a slight competitive advantage to professional athletes.
Studies like this are prone to endogeneity problems because success also feeds back on physical attraction. At the extreme, we know who Roger Federer is and that gets in the way of judging his attractiveness directly. More subtly, if you show me pictures of two anonymous athletes, the one who is more successful has probably also trained better, eaten better, been raised differently and these are all endogenous characteristics that affect attractiveness directly. Knowing that they correlate with success doesn’t tell us whether “success genes” have physically attractive manifestations.
One way to improve the study would be to look at adopted children. Show subjects pictures of the athletes’ biological parents and ask the subjects to rate the attractiveness of the parents. Then correlate the responses with the performance of the children. If these children were raised by randomly selected parents (obviously that is not exactly the case) then we would be picking up the effect of exogenous sources of physical attractiveness passed on only through the genes of the parents.
And why stop with success in sport. Physical attractiveness should be correlated with intelligence, social mobility, etc.
I am going to write an insurance contract with you. We agree that if an accident happens I will cover you unless you a type prone to accident or you don’t try hard enough to avoid an accident.
There are two ways we can implement these conditionals. We could investigate whether they hold at the time we sign the contract or we could wait until an accident happens. Since an accident is unlikely to happen, the second method often avoids unnecessary costs of investigation and makes it cheaper to enforce the contract. That means I can offer you a lower premium.
All of this assumes that the conditions that would nullify the contract are
- completely described either in the contract or in law,
- fully understood by the insured, and
- within the information set of the insured
Arguments against rescision can be based on any one of these three being violated. Certainly #1 is violated in practice if insurance companies are free to present any evidence suggestive of, for example, pre-existing conditions. Violations of #2 plagues all economic analysis of contracts, no doubt it is a problem here as well. And an argument against recision could be based on #3, even if we assume that contracts are complete and voluntary.
Indeed I believe that #3 is the basis for a response to the obvious “If allowing for recision is against the interests of the insured, why don’t insurers compete by offering no-rescision contracts.” These would have higher premiums for the reasons given above. Insurees would tend to reject these in favor of lower-premium rescision-permitting contracts when they are not aware of buried, jargon-laden, medical records that would nullify their coverage. In fact, the asymmetric access to this information superimposes an artificial asymmetric information problem on an insurance market that is already plagued by adverse selection.
Here’s a research problem: what does a competitive equilibrium look like in an insurance market where both types of contract can be offered? Assume that the insurer has superior information about documentation of pre-existing conditions, and conditions contract terms on its private information.
R. Duncan Luce has been elected fellow of the Econometric Society in the year 2009. He is 84. How could it take so long?
Here’s a model. There is a large set of economists and each year you have to decide which to admit to a select group of “fellows.” Assume away the problems of committee decision-making and say that an economist will be admitted if his achievements are above some standard. The problem is that there are many economists and its costly to investigate each one to see if they pass the bar.
So you pick a shortlist of candidates who are contenders and you investigate those. Some pass, some don’t. Now, the next problem is that there are many fellows and many non-fellows and its hard to keep track of exactly who is in and who is out. And again it’s costly to go and check every vita to find out who has not been admitted yet.
So when you pick your shortlist, you are including only economists who you think are not already fellows. Someone like Duncan Luce, who certainly should have been elected 30 years ago most likely was elected 30 years ago so you would never consider putting him on your shortlist.
Indeed, the simple rule of thumb you would use is to focus on young people for your shortlist. Younger economists are more likely to be both good enough and not already fellows.
Here is an experiment that as far as I know has not been done. (Please correct me if I am wrong.) Offer contestants the choice of two raffles. Raffle A pays the winner $1000, Raffle B pays the winner $1000+x where x is a positive number. Contestants must pick one of the raffles and can buy at most one raffle ticket. They choose simultaneously. There will be one winner from each raffle and the winners will be determined by random draw.
In equilibrium the expected payoff in the two raffles should be equalized. This means that more people should enter raffle B to compete away the extra $x prize money. My hypothesis is that in fact too many people will enter raffle B so that raffle A will have a higher expected payoff. I am thinking that the contestants will inusfficiently account for the strategic effect of free entry and will naively assume that B is the better choice. And I believe this effect will be large even when x is very small.
If this is true then it has important consequences for markets. Suppose two job market candidates are almost equally qualified but candidate A is a little better than candidate B. Candidate A will get too many interviews and candidate B will get too few. Candidate B’s slight disadvantage will be amplified by the market and will go too often unemployed.
In the economics job market for new PhD’s, economics departments are often asked by potential employers for rankings of their candidates. Departments are often unwilling to give more than coarse rankings and I believe that the effect I describe is the reason.
Despite my vast legion of Twitter followers, every one of my attempts to start a new trending topic has failed to catch on. Now I think I understand why.
Suppose that your goal is to coordinate attention on a topic that seems to be on a lot of minds. Attention is a scarce resource and you have only a limited number of topics you can highlight. But suppose, as with Twitter, you see what everyone is talking about. How do you decide which topics to point to?
You probably shouldn’t just count the total number of people talking on a given subject, counting everyone equally. You might think that you would instead give extra weight to the few people that everyone is listening to. Because whatever they say is more likely to be interesting to many, and will soon be on many minds. On Twitter, those would be the people with the most followers. But there is a strong case for doing the opposite and giving extra weight to people with few followers, especially people who are relatively isolated in the social network. This is not out of fairness (or pity) but actually as the efficient way to use your scarce resource.
Efficient coordination means making information public so that not just everyone knows it, but everyone knows that everyone knows it (etc.) If we all have to choose simultaneously what to focus our attention on and we want to be part of the larger conversation, then it matters what we think others are going to focus their attention on. Coordinating attention thus requires making it public what people are talking about.
Suppose we have two topics that are getting a lot of attention, but topic A is being discussed by well-connected individuals and topic B is being discussed more by a diverse group of isolated individuals. Topic A is already public because when you see it discussed by a central figure you know that all other of her followers are seeing it to. Topic B therefore has more to gain from elevating it to the status of trending topic, which immediately makes it public.
I always knew that my Twitter followers were among the wisest. Now I see the true depth of their wisdom. By adding to my follower numbers, they reduce the weight of my comments in the optimal weighting scheme thus ensuring that the crazy things I say will be ingored by the larger network. Join the cause.
We talked a lot before about designing a scoring system for sports like tennis. There is some non-fanciful economics based on such questions. Suppose you have two candidates for promotion and you want to promote the candidate who is most talented. You can observe their output but output is a noisy signal that depends not just on talent, but also effort both of which you cannot observe directly. (Think of them as associates in a law firm. You see how much they bill but you cannot disentangle hard work from talent. You must promote one to partner where hard work matters less and talent matters more.)
How do you decide whom to promote? The question is the same as how to design a scoring system in tennis to maximize the probability that the winner is the one who is most talented.
One aspect of the optimal contest seems clear. You should let them set the rules. If a candidate knows he has high ability he should be given the option to offer a handicap to his rival. Only a truly talented candidate would be willing to offer a handicap. So if you see that candidate A is willing to offer a higher handicap than candidate B, then you should reward A.
The rub is that you have to reward A, but give B a handicap. Is it possible to do both?
Let’s say you read a big book about recycling because you want to make an informed decision about whether it really makes sense to recycle. The book is loaded with facts: some pro, some con. You read it all, weigh the pluses and minuses and come away strongly convinced that recycling is a good thing.
But you are human and you can only remember so many facts. You are also a good manager so you optimally allow yourself to forget all of the facts and just remember the bottom line that you were quite convinced that you should recycle.
This is a stylized version of how we set personal policies. We have experiences, collect data, engage in debate and then come to conclusions. We remember the conclusions but not always the reasons. In most cases this is perfectly rational. The details matter only insofar as they lead us to the conclusions so as long as we remember the conclusions, we can forget about the reasons.
It has consequences however. How do you incorporate new arguments? When your spouse presents arguments against recycling, the only response you have available is “yes, that’s true but still I know recycling is the right thing to do.” And you are not just being stubborn. You are optimally responding to your limited memory of the reasons you considered carefully in the past.
In fact, we are probably built with a heuristic that hard-wires this optimal memory management. Call it cognitive-dissonance, confirmatory-bias, whatever. It is an optimal response to memory constraints to set policies and then stubbornly stick to them.
