
You are currently browsing the tag archive for the ‘maths’ tag.
From The New Yorker
Now, imagine an animal that emerges every twelve years, like a cicada. According to the paleontologist Stephen J. Gould, in his essay “Of Bamboo, Cicadas, and the Economy of Adam Smith,” these kind of boom-and-bust population cycles can be devastating to creatures with a long development phase. Since most predators have a two-to-ten-year population cycle, the twelve-year cicadas would be a feast for any predator with a two-, three-, four-, or six-year cycle. By this reasoning, any cicada with a development span that is easily divisible by the smaller numbers of a predator’s population cycle is vulnerable.
Prime numbers, however, can only be divided by themselves and one; they cannot be evenly divided into smaller integers. Cicadas that emerge at prime-numbered year intervals, like the seventeen-year Brood II set to swarm the East Coast, would find themselves relatively immune to predator population cycles, since it is mathematically unlikely for a short-cycled predator to exist on the same cycle. In Gould’s example, a cicada that emerges every seventeen years and has a predator with a five-year life cycle will only face a peak predator population once every eighty-five (5 x 17) years, giving it an enormous advantage over less well-adapted cicadas.
Have you seen Dragon Box? Once you do, you will be a believer in the power of technology for learning. I wasn’t before, I am now. My son is 6 and after about 4 hours of fun he can solve simple one-variable equations. Here’s how it works.
In the first level of Dragon Box you see a screen with two halves, “This side” and “That side.” There is a box on one side and some cards with random pictures on them. Your job is to isolate the box on one side, i.e. remove all the cards from the same side of the box.
This is very simple at the beginning because the only cards on that side are these funky vortex cards and all you have to do is touch them and they disappear. Vortex cards represent zero, but only you know that.
Later, other cards start appearing on the box’s side but then you learn something new: every card has a “night card” which graphically is represented by a card with the same picture but in negative exposure. Negative. If you slide a card onto its night card (or vice versa) the card turns into a vortex which you then dispatch with a subsequent tap.
Later again it happens that cards appear on the same side of the box but with no night card. But then you learn something new. You have cards in your deck and you can drag them onto either side of the screen. A card in your deck can be turned into its “night” version by tapping. Thus, you can eliminate a card on the box’s side by taking the same card from the deck, “nighting” it and then using it to vortex the offending card.
But any card you drag from the deck to one side of the screen you must drag to the other side also. This represents adding or subtracting a constant from both sides of an equation. After you have isolated the box on one side you have shown that the box equals the sum of all the cards remaining on the other side. But only you know these things.
Later still, cards appear with “partners,” i.e. another card right up next to it with an inexplicable dot connecting them. If the box has a partner you can eliminate the partner by dragging the corresponding card from your deck below a line which magically appears below the partners as you drag.
Dragon Box requires that whenever you drag a card from the deck below the line of any card, you must drag the same card below the lines of all card-groups on both sides of the screen. Once you have done that you can drag the card that is below the line onto its duplicate above the line and they together turn into a card with looks like a die with one pip showing. Such a card can then be dragged onto the box leaving only the box.
Here’s a demonstration (by me of an early level.)
The partners represent multiplication, the line represents division, the die with one pip represents the number 1 (i.e. the identity) and 1 times the box is just the box. After you have isolated the box you have shown that the box equals the sum and/or products of cards that appear on the other side. But only you know this.
Finally, the box mysteriously becomes the letter x. The cards lose their pretty pictures and become numbers and other constants. Night cards are now negative numbers. The vortex becomes zero and the die becomes the number 1. In the dividing zone between the two sides of the screen eventually appears an equals sign, and all the operations the child has learned now take their more familiar form and by pure sleight of hand he has been tricked into porting the very very simple logic of combining symbolic operations into the otherwise tedious world of “solve for x.”
I personally am astounded.
A few final thoughts.
- The reason a six-year-old can learn algebra with Dragon Box but could not before is that Dragon Box unbundles algebra from arithmetic. You don’t have to know what crazy-frog times lizard-fish equals to know that Box = CF times LF. Simplifying the right-hand-side is beside the point. Conventionally algebra comes after arithmetic because you need arithmetic to simplify the right-hand side.
- Actually what you learn from this is that algebra is far more elementary than arithmetic. My son can add numbers (up to one digit plus two digit) but just barely grasps the concept of multiplication. He has no idea what division is.
- Someone who already knows arithmetic can still learn algebra faster (and have more fun in the process) because Dragon Box shows how all the arithmetic can essentially be saved for the very end, modularizing the learning.
- Dragon box also rewards you if you solve the equation with the precise number of operations recommended. (This is usually the minimum number but not always.) This is a clever addition to the game because all of my kids refused out of pure pride to move on until they had solved each one in the right number of moves. Imagine asking a kid learning algebra to do that.
The last of Strogatz’ series blog entries on mathematics and it may be the best one:
For the Hilbert Hotel doesn’t merely have hundreds of rooms — it has an infinite number of them. Whenever a new guest arrives, the manager shifts the occupant of room 1 to room 2, room 2 to room 3, and so on. That frees up room 1 for the newcomer, and accommodates everyone else as well (though inconveniencing them by the move).
Now suppose infinitely many new guests arrive, sweaty and short-tempered. No problem. The unflappable manager moves the occupant of room 1 to room 2, room 2 to room 4, room 3 to room 6, and so on. This doubling trick opens up all the odd-numbered rooms — infinitely many of them — for the new guests.
Later that night, an endless convoy of buses rumbles up to reception. There are infinitely many buses, and worse still, each one is loaded with an infinity of crabby people demanding that the hotel live up to its motto, “There’s always room at the Hilbert Hotel.”
The manager has faced this challenge before and takes it in stride.
Read on for more highly accessible writing on Cantor’s infinities.
My daughter was learning about prime numbers and she had an exercise to identify all the prime numbers less than 100. I made a little game out of it with her by offering her 10 cents for each number correctly categorized as prime or composite within a fixed total time.
As she progressed through the numbers I noticed a pattern. It took her less time to guess that a number was composite than it took her to guess that it was prime. And of course there is a simple reason: you know that a number is composite once you find a proper factor, you know that a number is prime only when you are convinced that a proper factor does not exist.
But this was a timed-constrained task and waiting until she knows for sure that the number is prime is not an optimal strategy. She should guess that the number is prime once she thinks it is sufficiently likely that she won’t find any proper factor. And how long that will take depends on the average time it takes to find a proper factor.
In particular, if the average time before she guesses prime is larger than the average time before she guesses composite then she is not optimizing. Because if that were the case she should infer that the number is likely to be prime simply from the fact that she has spent more than the average time looking for a proper factor. At an optimum, any such introspective inference should be arbitraged away.
Its the same reason the lane going in the opposite direction is always flowing faster. This is a lovely article that works through the logic of conditional proportions. I really admire this kind of lucid writing about subtle ideas. (link fixed now, sorry.)
This phenomenon has been called the friendship paradox. Its explanation hinges on a numerical pattern — a particular kind of “weighted average” — that comes up in many other situations. Understanding that pattern will help you feel better about some of life’s little annoyances.
For example, imagine going to the gym. When you look around, does it seem that just about everybody there is in better shape than you are? Well, you’re probably right. But that’s inevitable and nothing to feel ashamed of. If you’re an average gym member, that’s exactly what you should expect to see, because the people sweating and grunting around you are not average. They’re the types who spend time at the gym, which is why you’re seeing them there in the first place. The couch potatoes are snoozing at home where you can’t count them. In other words, your sample of the gym’s membership is not representative. It’s biased toward gym rats.
Act as if you have log utility and with probability 1 your wealth will converge to infinity.
Sergiu Hart presented this paper at Northwestern last week. Suppose you are going to be presented an infinite sequence of gambles. Each has positive expected return but also a positive probability of a loss. You have to decide which gambles to accept and which gambles to reject. You can also invest purchase fractions of gambles: exposing yourself to some share 
Here is a simple investment strategy that guarantees infinite wealth. First, for every gamble 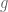

Next, when your wealth level is actually 
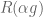
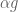
If you follow this rule then no matter what sequence of gambles appears you will never go bankrupt and your wealth will converge to infinity. What’s more, this is in some sense the most aggressive investment strategy you can take without running the risk of going bankrupt. Foster and Hart show that any investor that is willing to accept some gambles
Email is the superior form of communication as I have argued a few times before, but it can sure aggravate your self-control problems. I am here to help you with that.
As you sit in your office working, reading, etc., the random email arrival process is ticking along inside your computer. As time passes it becomes more and more likely that there is email waiting for you and if you can’t resist the temptation you are going to waste a lot of time checking to see what’s in your inbox. And it’s not just the time spent checking because once you set down your book and start checking you won’t be able to stop yourself from browsing the web a little, checking twitter, auto-googling, maybe even sending out an email which will eventually be replied to thereby sealing your fate for the next round of checking.
One thing you can do is activate your audible email notification so that whenever an email arrives you will be immediately alerted. Now I hear you saying “the problem is my constantly checking email, how in the world am i going to solve that by setting up a system that tells me when email arrives? Without the notification system at least I have some chance of resisting the temptation because I never know for sure that an email is waiting.”
Yes, but it cuts two ways. When the notification system is activated you are immediately informed when an email arrives and you are correct that such information is going to overwhelm your resistance and you will wind up checking. But, what you get in return is knowing for certain when there is no email waiting for you.
It’s a very interesting tradeoff and one we can precisely characterize with a little mathematics. But before we go into it, I want you to ask yourself a question and note the answer before reading on. On a typical day if you are deciding whether to check your inbox, suppose that the probability is p that you have new mail. What p is going to get you to get up and check? We know that you’re going to check if p=1 (indeed that’s what your mailbeep does, it puts you at p=1.) And we know that you are not going to check when p=0. What I want to know is what is the threshold above which its sufficiently likely that you will check and below which is sufficiently unlikely so you’ll keep on reading? Important: I am not asking you what policy you would ideally stick to if you could control your temptation, I am asking you to be honest about your willpower.
Ok, now that you’ve got your answer let’s figure out whether you should use your mailbeep or not. The first thing to note is that the mail arrival process is a Poisson process: the probability that an email arrives in a given time interval is a function only of the length of time, and it is determined by the arrival rate parameter r. If you receive a lot of email you have a large r, if the average time spent between arrivals is longer you have a small r. In a Poisson process, the elapsed time before the next email arrives is a random variable and it is governed by the exponential distribution.
Let’s think about what will happen if you turn on your mail notifier. Then whenever there is silence you know for sure there is no email, p=0 and you can comfortably go on working temptation free. This state of affairs is going to continue until the first beep at which point you know for sure you have mail (p=1) and you will check it. This is a random amount of time, but one way to measure how much time you waste with the notifier on is to ask how much time on average will you be able to remain working before the next time you check. And the answer to that is the expected duration of the exponential waiting time of the Poisson process. It has a simple expression:
Expected time between checks with notifier on =
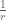
Now let’s analyze your behavior when the notifier is turned off. Things are very different now. You are never going to know for sure whether you have mail but as more and more time passes you are going to become increasingly confident that some mail is waiting, and therefore increasingly tempted to check. So, instead of p lingering at 0 for a spell before jumping up to 1 now it’s going to begin at 0 starting from the very last moment you previously checked but then steadily and continuously rise over time converging to, but never actually equaling 1. The exponential distribution gives the following formula for the probability at time T that a new email has arrived.
Probability that email arrives at or before a given time T =
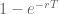
Now I asked you what is the p* above which you cannot resist the temptation to check email. When you have your notifier turned off and you are sitting there reading, p will be gradually rising up to the point where it exceeds p* and right at that instant you will check. Unlike with the notification system this is a deterministic length of time, and we can use the above formula to solve for the deterministic time T at which you succumb to temptation. It’s given by
Time between checks when the notifier is off =

And when we compare the two waiting times we see that, perhaps surprisingly, the comparison does not depend on your arrival rate r (it appears in the numerator of both expressions so it will cancel out when we compare them.) That’s why I didn’t ask you that, it won’t affect my prescription (although if you receive as much email as I do, you have to factor in that the mail beep turns into a Geiger counter and that may or may not be desirable for other reasons.) All that matters is your p* and by equating the two waiting times we can solve for the crucial cutoff value that determines whether you should use the beeper or not.
The beep increases your productivity iff your p* is smaller than
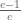
This is about .63 so if your p* is less than .63 meaning that your temptation is so strong that you cannot resist checking any time you think that there is at least a 63% chance there is new mail waiting for you then you should turn on your new mail alert. If you are less prone to temptation then yes you should silence it. This is life-changing advice and you are welcome.
Now, for the vapor mill and feeling free to profit, we do not content ourselves with these two extreme mechanisms. We can theorize what the optimal notification system would be. It’s very counterintuitive to think that you could somehow “trick” yourself into waiting longer for email but in fact even though you are the perfectly-rational-despite-being-highly-prone-to-temptation person that you are, you can. I give one simple mechanism, and some open questions below the fold.
- (Mathematics) Not very good. He spends a good deal of time apparently in investigations in advanced mathematics to the neglect of his elementary work. A sound ground work is essential in any subject. His work is dirty.
- (Greek) He seems to find the subject a very hard one & most of his work has been very poor in quality. I think he tries.
- (Latin) His Latin work is for the most part careless & slovenly: he can do much better when he tries.
- (“House report”) No doubt he is a strange mixture: trying to build a roof before he has laid the foundations. Having secured one privileged exemption, he is mistaken in acting as if idleness and indifference will procure further release from uncongenial subjects.
The pointer came from Josh Gans on Google+
Almost every kind of race works like this: we agree on a distance and we see who can complete that distance in the shortest time. But that is not the only way to test who is the fastest. The most obvious alternative is to switch the roles of the two variables: fix a time and see who can go the farthest in that span of time.
Once you think of that the next question to ask is, does it matter? That is, if the purpose of the race is to generate a ranking of the contestants (first place, second place, etc) then are there rankings that can be generated using a fixed-time race that cannot be replicated using an appropriately chosen fixed-distance race?
I thought about this and here is a simple way to formalize the question. Below I have represented three racers. A racer is characterized by a curve which shows for every distance how long it takes him to complete that distance.

Now a race can be represented in the same diagram. For example, a standard fixed-distance race looks like this.

The vertical line indicates the distance and we can see that Green completes that distance in the shortest time, followed by Black and then Blue. So this race generates the ranking Green>Black>Blue. A fixed-time race looks like a horizontal line:

To determine the ranking generated by a fixed-time race we move from right to left along the horizontal line. In this time span, Black runs the farthest followed by Green and then Blue.
(You may wonder if we can use the same curve for a fixed-time race. After all, if the racers are trying to go as far as possible in a given length of time they would adjust their strategies accordingly. But in fact the exact same curve applies. To see this suppose that Blue finishes a d-distance race in t seconds. Then d must be the farthest he can run in t seconds. Because if he could run any farther than d, then it would follow that he can complete d in less time than t seconds. This is known as duality by the people who love to use the word duality.)
OK, now we ask the question. Take an arbitrary fixed-time race, i.e. a horizontal line, and the ordering it generates. Can we find a fixed-distance race, i.e. a vertical line that generates the same ordering? And it is easy to see that, with 3 racers, this is always possible. Look at this picture:

To find the fixed-distance race that would generate the same ordering as a given fixed-time race, we go to the racer who would take second place (here that is Black) and we find the distance he completes in our fixed-time race. A race to complete that distance in the shortest time will generate exactly the same ordering of the contestants. This is illustrated for a specific race in the diagram but it is easy to see that this method always works.
However, it turns out that these two varieties of races are no longer equivalent once we have more than 3 racers. For example, suppose we add the Red racer below.

And consider the fixed-time race shown by the horizontal line in the picture. This race generates the ordering Black>Green>Blue>Red. If you study the picture you will see that it is impossible to generate that ordering by any vertical line. Indeed, at any distance where Blue comes out ahead of Red, the Green racer will be the overall winner.
Likewise, the ordering Green>Black>Red>Blue which is generated by the fixed-distance race in the picture cannot be generated by any fixed-time race.
So, what does this mean?
- The choice of race format is not innocuous. The possible outcomes of the race are partially predetermined what would appear to be just arbitrary units of measurement. (Indeed I would be a world class sprinter if not for the blind adherence to fixed-distance racing.)
- There are even more types of races to consider. For example, consider a ray (or any curve) drawn from the origin. That defines a race if we order the racers by the first point they cross the curve from below. One way to interpret such a race is that there is a pace car on the track with the racers and a racer is eliminated as soon as he is passed by the pace car. If you play around with it you will see that these races can also generate new orderings that cannot be duplicated. (We may need an assumption here because duality by itself may not be enough, I don’t know.)
- That raises a question which is possibly even a publishable research project: What is a minimal set of races that spans all possible races? That is, find a minimal set of races such that if there is any group of contestants and any race (inside or outside the minimal set) that generates some ordering of those contestants then there is a race in the set which generates the same ordering.
- There are of course contests that are time based rather than quantity based. For example, hot dog eating contests. So another question is, if you have to pick a format, then which kinds of feats better lend themselves to quantity competition and which to duration competition?
From Presh Talwalker:
In poker tournaments, everyone gets a fair shot at holding the dealer position as seats are assigned randomly.
In home games, an attempt is also made to assign the dealer spot randomly. There are many methods to choosing the dealer. One of the common methods is dealing to the first ace. It works like this: the host deals a card to each player, face up, and continues to deal until someone receives an ace. This player gets to start the game as dealer.
The question is: does dealing to the first ace give everyone an equal chance to be dealer? Is this a fair system?
Answer: it’s not. Presh goes through the full analysis, but here’s a simple way to see why. Suppose you have 5 players at the table and you are dealing from a deck of 5 cards with 2 aces in it. Every time you deal there will be two people with aces. But the person who gets to be dealer is the one who is closest to the host’s left. If the deal went in the other direction, someone closer to the host’s right would be dealer.
It can’t be fixed by tossing a coin to decide which direction to deal because that would disadvantage players sitting directly across from the dealer. You need to randomly choose the first person to deal to. But if you have a trustworthy device for doing that, you don’t need to bother with the aces.

I don’t mean breaking and entering. It’s New Years Eve — 2PM on New Years Eve — and after heading out for a quick lunch I return to find The Jacobs Center locked for the weekend. There is a separate electronic key to the building and I have one somewhere but I never need it so I don’t carry it around with me. So I have to stand in the cold and wait for somebody to enter or exit the building and let me in.
There are two entrances so the question is which one to stand by and wait. I wait for a while at the main entrance and then decide to try my luck at the next one on the other side of the building, about a 2 minute walk. Of course on the way I am imagining that someone must be leaving from the first entrance just as it passed out of sight. When I get to the other entrance I find that there’s just as little activity there as at the first one. After a while I give up again and go back to the first.
I have a sinking feeling as I am walking back that I am violating some basic rationality postulate to have dropped the first alternative only to switch back to it again. But it’s not hard to rationalize switching, even indefinite switching with a simple model of uncertain arrival rates.
At each entrance there is a random arrival process, say Poisson, which produces a comer or goer with some given flow rate. It’s random so even if the arrivals are frequent on average its still possible that there is a long wait just because of bad luck. Because it’s an unusual day I don’t know for sure what the arrival rates are at the two entrances so the best I can do is form a subjective distribution.
As time passes I learn only about the door I am watching and what I am learning is that the arrival rate is slower than I thought. Every moment that passes and I am still out in the cold the current door’s expected arrival rate is continuously dropping. There comes a point in time when it drops low enough that I want to switch to the other door. The expected arrival rate at the other door hasn’t changed becuase I haven’t learned anything about it. I give up and walk to the other door once the estimated rate at the current door drops far enough below that it is worth 2 minutes of walking (and no chance of getting in during that time.) In fact, this may happen before the current door’s expected arrival rate drops below that of the other door. (Due to option value. See below.)
Once at the other door I start to learn about it and I stop learning about the first door. Again, as time passes its estimated arrival rate drops while that of the first door remains constant. There is again another threshold after which I return to the first. Etc. Until I finally give up and throw a brick through the Kellogg student lounge window.
Observation: Consider the threshold at which I switch from door 1 to door 2. That is based on a comparison of the value of staying put versus the value of switching. The value of switching has built into it the option value of being able to switch back. You can see the role of this option value by considering a truncated problem where once I switch doors I am unable to switch back. Relative to that problem, the option of switching back makes me switch more frequently. Because without the option to switch back, I want to hold on to the current option until I am certain that it’s a loser before giving it up for good.
A mathematician who was very important for economic theory, he died last week. Here are a number of thoughtful remembrances.
If I missed yours I am very sorry, please post a link in the comments.

What explains Jamiroquai? How can an artist be talented enough to have a big hit but not be talented enough to stay on the map? You can tell stories about market structure, contracts, fads, etc, but there is a statistical property that comes into play before all of that.
Suppose that only the top .0001% of all output gets our attention. These are the hits. And suppose that artists are ordered by their talent, call it τ. Talent measures the average quality of an artist’s output, but the quality of an individual piece is a draw from some distribution with mean τ.
Suppose that talent itself has a normal distribution within the population of artists. Let’s consider the talent level τ which is at the top .001 percentile. That is, only .001% of the population are more talented than τ. A striking property of the normal distribution is the following. Among all people who are more talented than τ, a huge percentage of them are just barely more talented than τ. Only a very small percentage, say 1% of the top .001% are significantly more talented than τ, they are the superstars. (See the footnote below for a precise statement of this fact.)
These superstars will consistently produce output in the top .0001%. They will have many hits. But they make up only 1% of the top .001% and so they make up only .00001% of the population. They can therefore contribute at most 10% of the hits.
The remaining 90% of the hits will be produced by artists who are not much more talented than τ. The most talented of these consist of the remaining 99% of the top .001%, i.e. close to .001% of the population. With all of these artists who are almost equal in terms of talent competing to perform in the top .0001%, each of these has at most a 1 in 10 chance of doing it once. A 1 in 100 chance of doing it twice, etc.
_____________________
(*A more precise version of this statement is something like the following. For any e>0 as small as you wish and y<100% as large as you wish, if you pick x big enough and you ask what is the conditional probability that someone more talented than x is not more talented than x+e, you can make that probability larger than y. This feature of the normal distribution is referred to as a thin tail property.)
I’ve been thinking about the Sleeping Beauty problem a lot and I have come up with a few variations that help with intuition. So far I don’t see any clear normative argument why your belief should be anything in particular (although some beliefs are obviously wrong.) My original argument was circular because I wanted to prove that your willingness to be reveals that you assign equal probability but I essentially assumed you assigned equal probability in calculating the payoffs to those bets.
Nevertheless the argument does show that the belief of 1/2 is a consistent belief in that it leads to betting behavior with a resulting expected payoff which is correct. On the other hand a belief of 1/3 is not consistent. If, upon waking, you assign probability 1/3 to Heads you will bet on Tails and you will expect your payoff to be (2/3)2 – (1/3)1 = $1. But your true expected payoff from betting tails is 50 cents. This means that you are vulnerable to the following scheme. At the end of their speech, the researchers add “In order to participate in this bet you must agree to pay us 75 cents. You will pay us at the end of the experiment, and only once. But you must decide now, and if you reject the deal in any of the times we wake you up, the bet is off and you pay and receive nothing.”
If your belief is 1/3 you will agree to pay 75 cents because you will expect that your net payoff will be $1 – 75 cents = 25 cents. But by agreeing the deal you are actually giving yourself an expected loss of 25 cents (50 cents – 75 cents.) If your belief is 1/2 you are not vulnerable to these Dutch books.
Here are the variations.
- (Clones in their jammies) The speech given by the researchers is changed to the following. “We tossed a fair coin to decide whether we would clone you, and then wake up both instances of you. The clone would share all of your memories, and indeed you may be that clone. Tails: clone, Heads: no clone (but still we would wake you and give you this speech and offer.) You (and your clone if Tails) can bet on the coin. In the event of tails, your payoff will be the sum of the payoffs from you and your clone’s bet (and the same for you if you are the clone.)”
- (Changing the odds) Suppose that the stakes in the event of Heads is $1.10. Now those with belief 1/2 strictly prefer to bet Heads (in the original example they were indifferent.) And this gives them an expected loss, whereas the strategy of betting Tails every time would still give an expected gain. This exaggerates the weirdness but it is not a proof that 1/2 is the wrong belief. The same argument could be applied to the clones where we would have something akin to a Prisoner’s dilemma. It is not an unfamiliar situation to have an individual incentive to do something that is bad for the pair.
- Suppose that the coin is not fair, and the probability of Tails is 1/n. But in the event of Tails you will be awakened n times. The simple counting exercise that leads to the 1/3 belief seemed to rely on the fair coin in order to treat each awakening equal. Now how do you do it?
- The experimenters give you the same speech as before but add this: “each time we wake you, you will place your bet BUT in the event of Tails, at your second awakening, we will ignore your choice and substitute a bet on Tails on your behalf.” Now your bet only matters in the first awakening. How would you bet now? (“Thirders” who are doing simple counting would probably say that, conditional on the first awakening, the probability of Heads is 1/2. Is it?)
- Same as 4 but the bet is substituted on the first awakening in the event of Tails. Now your bet only matters if the coin came up Heads or it came up Tails and this is the second awakening. Does it make any difference?
Via Robert Wiblin here is a fun probability puzzle:
The Sleeping Beauty problem: Some researchers are going to put you to sleep. During the two days that your sleep will last, they will briefly wake you up either once or twice, depending on the toss of a fair coin (Heads: once; Tails: twice). After each waking, they will put you to back to sleep with a drug that makes you forget that waking.
The puzzle: when you are awakened, what probability do you assign to the coin coming up heads? Robert discusses two possible answers:
First answer: 1/2, of course! Initially you were certain that the coin was fair, and so initially your credence in the coin’s landing Heads was 1/2. Upon being awakened, you receive no new information (you knew all along that you would be awakened). So your credence in the coin’s landing Heads ought to remain 1/2.
Second answer: 1/3, of course! Imagine the experiment repeated many times. Then in the long run, about 1/3 of the wakings would be Heads-wakings — wakings that happen on trials in which the coin lands Heads. So on any particular waking, you should have credence 1/3 that that waking is a Heads-waking, and hence have credence 1/3 in the coin’s landing Heads on that trial. This consideration remains in force in the present circumstance, in which the experiment is performed just once.
Let’s approach the problem from the decision-theoretic point of view: the probability is revealed by your willingness to bet. (Indeed, when talking about subjective probability as we are here, this is pretty much the only way to define it.) So let me describe the problem in slightly more detail. The researchers, upon waking you up give you the following speech.
The moment you fell asleep I tossed a fair coin to determine how many times I would wake you up. If it came up heads I would wake you up once and if it came up tails I would wake you up twice. In either case, every time I wake you up I will tell you exactly what I am telling you right now, including offering you the bet which I will describe next. Finally, I have given you a special sleeping potion that will erase your memory of this and any previous time I have awakened you. Here is the bet: I am offering even odds on the coin that I tossed. The stakes are $1 and you can take either side of the bet. Which would you like? Your choice as well as the outcome of the coin are being recorded by a trustworthy third party so you can trust that the bet will be faithfully executed.
Which bet do you prefer? In other words, conditional on having been awakened, which is more likely, heads or tails? You might want to think about this for a bit first, so I will put the rest below the fold.
You are preparing two dishes. For the first you will put 1 tsp. cornstarch in a medium sized bowl and for the second you will put 1/2 tsp. cornstarch in a small bowl. By mistake you put the 1 tsp. cornstarch in the small bowl. You have a full set of of measuring spoons, any number of spare bowls, and a box of cornstarch. What is the most efficient way to get back on track? Answer after the jump.
Is it an infinite number of monkeys, or is it infinitely-lived monkeys? If what you want is Shakespeare with probability 1 it matters. Because Hamlet is a fixed finite string of characters. That means the monkey has to stop typing when the string is complete. If we model the monkey as a process which every second taps a random key from the keyboard according to a fixed probability distribution, then to produce the Dithering Dane he must eventually repeat the space bar (or equivalently no key at all) until his terminal date.
If that terminal date is infinity, i.e. the monkey is given infinite time, then this event has probability zero. On the other hand, an infinite number of monkeys who each live long enough, but not infinitely long, will Exuent with probability 1 as desired.
(If your criterion is simply that the text of Hamlet appear somewhere in the output string, then a) you are sorely lacking in ambition and b) it no longer matters which version of infinity you have.)
Mortarboard Missive: Marginal Revolution.
Via kottke, here is a paper proposing A Unified Theory of Superman’s Powers. The abstract reads as follows.
Since Time immemorial, man has sought to explain the powers of Kal-El, a.k.a. Superman. Siegel et al. Supposed that His mighty strength stems from His origin on another planet whose density and as a result, gravity, was much higher than our own. Natural selection on the planet of krypton would therefore endow Kal El with more efficient muscles and higher bone density; explaining, to first order, Superman’s extraordinary powers. Though concise, this theory has proved inaccurate. It is now clear that Superman is actually flying rather than just jumping really high; and His freeze-breath, x-ray vision, and heat vision also have no account in Seigel’s theory.
In this paper we propose a new unfied theory for the source of Superman’s powers; that is to say, all of Superman’s extraordinary powers are manifestation of one supernatural ability, rather than a host. It is our opinion that all of Superman’s recognized powers can be unified if His power is the ability to manipulate, from atomic to kilometer length scales, the inertia of His own and any matter with which He is in contact.
The paper goes on to show how the theory can explain Superman’s super strength, ability to fly, super senses, and even his heat vision and freeze breath. It’s an elegant theory but the analysis has one significant gap. It is not enough to find a simple principle from which all of Superman’s powers follow. It is necessary to also show that the principle would not imply powers that Superman does not have.
If we do not insist on the latter, then there is an even simpler theory that does the trick: Superman can do everything. (Although that comes with its own difficulties.)
Its a standard example of a game that has no Nash equilibrium. But what exactly are the rules of the game? How about these:
You have fifteen seconds. Using standard math notation, English words, or both, name a single whole number—not an infinity—on a blank index card. Be precise enough for any reasonable modern mathematician to determine exactly what number you’ve named, by consulting only your card and, if necessary, the published literature.
Hmm… maybe it does have a Nash equilbirium. But after reading the article (highly recommended), I am still not sure. I think it comes down to whether or not the players are Turing machines. (Fez flip: The Browser)
A post at Language Log explores the use of mathematics in linguistics. It closes with
Anyhow, my conclusion is that anyone interested in the rational investigation of language ought to learn at least a certain minimum amount of mathematics.
Unfortunately, the current mathematical curriculum (at least in American colleges and universities) is not very helpful in accomplishing this — and in this respect everyone else is just as badly served as linguists are — because it mostly teaches thing that people don’t really need to know, like calculus, while leaving out almost all of the things that they will really be able to use. (In this respect, the role of college calculus seems to me rather like the role of Latin and Greek in 19th-century education: it’s almost entirely useless to most of the students who are forced to learn it, and its main function is as a social and intellectual gatekeeper, passing through just those students who are willing and able to learn to perform a prescribed set of complex and meaningless rituals.)
Before getting into economics and after getting out of physics, I took calculus and found it very useful and interesting for its own sake. I do see that the way calculus is taught in the US is geared toward engineers and physicists, but I have a hard time thinking of what mathematics would substitute for calculus in the undergraduate curriculum if the goal was to teach students something useful. It can’t be analysis or topology. I took abstract algebra as an undergraduate and found it esoteric and boring. Discrete mathematics? OK maybe statistics, but don’t you need integration for that? Help me out here, if you had the choice, what would you replace calculus with? And remember the goal is to teach something useful.
“These are relatively simple physical equations, so you program them into the computer and therefore kind of let the computer animate things for you, using those physics,” said May. “So in every frame of the animation, (the computer can) literally compute the forces acting on those balloons, (so) that they’re buoyant, that their strings are attached, that wind is blowing through them. And based on those forces, we can compute how the balloon should move.”
This process is known as procedural animation, and is described by an algorithm or set of equations, and is in stark contrast to what is known as key frame animation, in which the animators explicitly define the movement of an object or objects in every frame.
Why stop there? Next, we can use models from the behavioral sciences, program a few equations and let the characters, dialog, and action animate themselves by following the solution of the model. Don’t believe me? Here’s how to procedurally animate Romeo and Juliet.

{kind=link}