
You are currently browsing the tag archive for the ‘vapor mill’ tag.
I was talking to someone about matching mechanisms and the fact that strategy-proof incentives are often incompatible with efficiency. The question came up as to why we insist upon strategy-proofness, i.e. dominant strategy incentives as a constraint. If there is a trade-off between incentives and efficiency shouldn’t that tradeoff be in the objective function? We could then talk about how much we are willing to compromise on incentives in order to get some marginal improvement in efficiency.
For example, we might think that agents are willing to tell the truth about their preferences as long as manipulating the mechanism doesn’t improve their utility by a large amount. Then we should formalize a tradeoff between the epsilon slack in incentives and the welfare of the mechanism. The usual method of maximizing welfare subject to an incentive constraint is flawed because it prevents us from thinking about the problem in this way.
That sounded sensible until I thought about it just a little bit longer. If you are a social planner you have some welfare function, let’s say V. You want to choose a mechanism so that the resulting outcome maximizes V. And you have a theory about how agents will play any mechanism you choose. Let’s say that for any mechanism M, O(M) describes the outcome or possible outcomes according to your theory. This can be very general: O(M) could be the set of outcomes that will occur when agents are epsilon-truth-tellers, it could be some probability distribution over outcomes reflecting that you acknowledge that your theory is not very precise. And if you have the idea that incentives are flexible, O can capture that: for mechanisms M that have very strong incentive properties, O(M) will be a small set, or a degenerate probability distribution, whereas for mechanisms M that compromise a bit on incentives O(M) will be a larger set or a more diffuse probability distribution. And if you believe in a tradeoff between welfare and incentives, your V applied to O(M) can encode that by quantifying the loss associated with larger sets O(M) compared to smaller sets O(M).
But whatever your theory is you can represent it by some O(.) function. Then the simplest formulation of your problem is: choose M to maximize V(O(M)). And then we can equivalently express that problem in our standard way: choose an outcome (or set of outcomes, or probability distribution over outcomes ) O to maximize V(O) subject to the constraint that there exists some mechanism M for which O = O(M). That constraint is called the incentive constraint.
Incentives appear as a constraint, not in the objective. Once you have decided on your theory O, it makes no sense to talk about compromising on incentives and there is no meaningful tradeoff between incentives and welfare. While we might, as a purely theoretical exercise, comment on the necessity of such a tradeoff, no social planner would ever care to plot a “frontier” of mechanisms whose slope quantifies a rate of substitution between incentives and welfare.
I stopped following Justin Wolfers on Twitter. Not because I don’t want his tweets, they are great, but because everyone I follow also follows Justin. They all retweet his best tweets and I see those so I am not losing anything.
Which made me wonder how increasing density of the social network affects how informed people are. Suppose you are on a desert island but a special desert island which receives postal deliveries. You can get informed by subscribing to newspapers but you can’t talk to anybody. As long as the value v of being informed exceeds the cost c you will subscribe.
Compare that to an individual in a dense social network who can either pay for a subscription or wait around for his friends to get informed and find out from them. It won’t be an equilibrium for everybody to subscribe. You would do better by saving the cost and learning from your friends. Likewise it can’t be that nobody subscribes.
Instead in equilibrium everybody will subscribe with some probability between 0 and 1. And there is a simple way to compute that probability. In such an equilibrium you must be indifferent between subscribing and not subscribing. So the total probability that at least one of your friends subscribes must be the q that satisfies vq = v – c. The probability of any one individual subscribing must of course be lower than q since q is the total probability that at least one subscribes. So if you have n friends, then they each subscribe with the probability p(n) satisfiying 1 – [1 – p(n)]^n = q.
(Let’s pause while the network theorists all rush out of the room to their whiteboards to solve the combinatorial problem of making these balance out when you have an arbitrary network with different nodes having a different number of neighbors.)
This has some interesting implications. Suppose that the network is very dense so that everybody has many friends. Then everyone is less likely to subscribe. We only need a few people to be Justin Wolfers’ followers and retweet all of his best tweets. Formally, p(n) is decreasing in n.
That by itself is not such a bad thing. Even though each of your friends subscribes with a lower probability, on the positive side you have more friends from whom you can indirectly get informed. The net effect could be that you are more likely to be informed.
But in fact the net effect is that a denser network means that people are on average less informed, not more. Because if the network density is such that everyone has (on average) n friends, then everybody subscribes with probability p(n) and then the probability that you learn the information is q + (1-q)p(n). (With probability q one of your friends subscribes and you learn from them, and if you don’t learn from a friend then you become informed only if you have subscribed yourself which you do with probability p(n).) Since p(n) gets smaller with n, so does the total probability that you are informed.
Another way of saying this is that, contrary to intuition, if you compare two otherwise similar people, those who are well connected within the network have a tendency to be less informed than those who are in a relatively isolated part of the network.
All of this is based on a symmetric equilibrium. So one way to think about this is as a theory for why we see hierachies in information transmission, as represented by an asymmetric equilibrium in which some people subscribe for sure and others are certain not to. At the top of the hierarchy there is Justin Wolfers. Just below him we have a few people who follow him. They have a strict incentive to follow him because so few others follow him that the only way to be sure to get his tweets is to follow him directly. Below them is a mass of people who follow these “retailers.”
I was working on a paper, writing the introduction to a new section that deals with an extension of the basic model. It’s a relevant extension because it fits many real-world applications. So naturally I started to list the many real-world applications.
“This applies to X, Y, and….” hmmm… what’s the Z? Nothing coming to mind.
But I can’t just stop with X and Y. Two examples are not enough. If I only list two examples then the reader will know that I could only think of two examples and my pretense that this extension applies to many real-world applications will be dead on arrival.
I really only need one more. Because if I write “This applies to X, Y, Z, etc.” then the Z plus the “etc.” proves that there is in fact a whole blimpload of examples that I could have listed and I just gave the first three that came to mind, then threw in the etc. to save space.
If you have ever written anything at all you know this feeling. Three equals infinity but two is just barely two.
This is largely an equilbrium phenomenon. A convention emerged according to which those who have an abundance of examples are required to prove it simply by listing three. Therefore those who have listed only two examples truly must have only two.
Three isn’t the only threshold that would work as an equilibrium. There are many possibilities such as two, four, five etc. (ha!) Whatever threshold N we settle on, authors will spend the effort to find N examples (if they can) and anything short of that will show that they cannot.
But despite the multiplicity I bet that the threshold of three did not emerge arbitrarily. Here is an experiment that illustrates what I am thinking.
Subjects are given a category and 1 minute, say. You ask them to come up with as many examples from that category they can think of in 1 minute. After the 1 minute is up and you count how many examples they came up with you then give them another 15 minutes to come up with as many as they can.
With these data we would do the following. Plot on the horizontal axis the number x of items they listed in the first minute and on the vertical axis the number E(y|x) equal to the empirical average number y of items they came up with in total conditional on having come up with x items in the first minute.
I predict that you will see an anomalous jump upwards between E(y|2) and E(y|3).
This experiment does not take into account the incentive effects that come from the threshold. The incentives are simply to come up with as many examples as possible. That is intentional. The point is that this raw statistical relation (if it holds up) is the seed for the equilibrium selection. That is, when authors are not being strategic, then three-or-more equals many more than two. Given that, the strategic response is to shoot for exactly three. The equilibrium result is that three equals infinity.

Usain Bolt was disqualified in the final of the 100 meters at the World Championships due to a false start. Under current rules, in place since January 2010, a single false start results in disqualification. By contrast, prior to 2003 each racer who jumped the gun would be given a warning and then disqualified after a second false start. In 2003 the rules were changed so that the entire field would receive a warning after a false start by any racer and all subsequent false starts would lead to disqualification.
Let’s start with the premise that an indispensible requirement of sprint competition is that all racers must start simultaneously. That is, a sprint is not a time trial but a head-to-head competition in which each competitor can assess his standing at any instant by comparing his and his competitors’ distance to a fixed finished line.
Then there must be penalty for a false start. The question is how to design that penalty. Our presumed edict rules out marginally penalizing the pre-empter by adding to his time, so there’s not much else to consider other than disqualification. An implicit presumption in the pre-2010 rules was that accidental false starts are inevitable and there is a trade-off between the incentive effects of disqualification and the social loss of disqualifying a racer who made an error despite competing in good faith.
(Indeed this trade-off is especially acute in high-level competitions where the definition of a false start is any racer who leaves less than 0.10 seconds after the report of the gun. It is assumed to be impossible to react that fast. But now we have a continuous variable to play with. How much more impossible is it to react within .10 seconds than to react within .11 seconds? When you admit that there is a probability p>0, increasing in the threshold, that a racer is gifted enough to reach within that threshold, the optimal incentive mechanisn picks the threshold that balances type I and type II errors. The maximum penalty is exacted when the threshold is violated.)
Any system involving warnings invites racers to try and anticipate the gun, increasing the number of false starts. But the pre- and post-2003 rules play out differently when you think strategically. Think of the costs and benefits of trying to get a slightly faster start. The warning means that the costs of a potential false start are reduced. Instead of being disqualified you are given a second chance but are placed in the dangerous position of being disqualified if you false start again. In that sense, your private incentives to time the gun are identical whether the warning applies only to you or to the entire field. But the difference lies in your treatment relative to the rest of the field. In the post-2003 system that penalty will be applied to all racers so your false start does not place you at a disadvantage.
Thus, both systems encourage quick starts but the post 2003 system encouraged them even more. Indeed there is an equilibrium in which false starts occur with probability close to 1, and after that all racers are warned. (Everyone expects everyone else to be going early, so there’s little loss from going early yourself. You’ll be subject to the warning either way.) After that ceremonial false start the race becomes identical to the current, post 2010, rule in which a single false start leads to disqualification. My reading is that equilibrium did indeed obtain and this was the reason for the rule change. You could argue that the pre 2003 system was even worse because it led to a random number of false starts and so racers had to train for two types of competition: one in which quick starts were a relevant strategy and one in which they were not.
Is there any better system? Here’s a suggestion. Go back to the 2003-2009 system with a single warning for the entire field. The problem with that system was that the penalty for being the first to false start was so low that when you expected everyone else to be timing the gun your best response was to time the gun as well. So my proposal is to modify that system slightly to mitigate this problem. Now, if racer B is the first to false start then in the restart if there is a second false start by, say racer C, then racer C and racer B are disqualified. (In subsequent restarts you can either clear the warning and start from scratch or keep the warning in place for all racers.)
Here’s a second suggestion. The racers start by pushing off the blocks. Engineer the blocks so that they slide freely along their tracks and only become fixed in place at the precise moment that the gun is fired.
(For the vapor mill, here are empirical predictions about the effect of previous rule-regimes on race outcomes:
- Comparing pre-2003, under the 2003-2009 you should see more races with at least one false start but far fewer total false starts per race. The current rules should have the least false starts.
- Controlling for trend (people get faster over time) if you consider races where there was no false start, race times should be faster 2003-2009 than pre-2003. That ranking reverses when you consider races in which there was at least one false start. Controlling for Usain Bolt, times should be unambiguously slower under current rules.)
Experiments concerning the effect of publishing calorie counts on restaurant menus tend to show little effect on choices. In the experiments that I know of, choices before and after publishing calorie counts are compared. But this form of test cannot be considered conclusive. Some people were overestimating the calories and they might cut back, some were underestimating and they might eat more. There is no reason to expect that the aggregate change should be positive or negative.
A better experiment would be to use a restaurant where calorie counts are already published and manipulate them. Will people change their choices when you add 5% to the reported calories? 10%? What is the elasticity? It’s a safe guess that there would be little response for small changes and a large response for very large changes. Any response at all would prove that their is value is publishing calorie counts because it would prove that this information is useful for choices.
The only question that would remain is how those welfare gains measure up against the cost of collecting and publicizing the information.
Bandwagon effects are hard to prove. If an artist is popular, does that popularity by itself draw others in? Are you more likely to enjoy a movie, restaurant, blog just because you know that lots of other people like it to? It’s usually impossible to distinguish that theory from the simpler hypothesis: the reason it was popular in the first place was that it was good and that’s why you are going to like it too.
Here’s an experiment that would isolate bandwagon effects. Look at the Facebook like button below this post. I could secretly randomly manipulate the number that appears on your screen and then correlate your propensity to “like” with the number that you have seen. The bandwagon hypothesis would be that the larger number of likes you see increases your likeitude.

Clearly the reason that sex is so pleasurable is because that motivates us to have a lot of it. It is evolutionarily advantageous to desire the things that make us more fit. Sex feels good, we seek that feeling, we have a lot of sex, we reproduce more.
But that is not the only way to get motivated. It is also advantageous to derive pleasure directly from having children. We see children, we sense the joy we would derive from our own children and we are motivated to do what’s necessary to produce them, even if we had no particular desire for the intermediate act of sex.
And certainly both sources of motivation operate on us, but in different proportions. So it is interesting to ask what determines the optimal mix of these incentives. One alternative is to reward an intermediate act which has no direct effect on fitness but can, subject to idiosyncratic conditions together with randomness, produce a successful outcome which directly increases fitness. Sex is such an act. The other alternative is to confer rewards upon a successful outcome (or penalties for a failure.) That would mean programming us with a desire and love for children.
The tradeoff can be understood using standard intuitions from incentive theory. The rewards are designed to motivate us to take the right action at the right time. The drawback of rewarding only the final outcome is that it may be too noisy a signal of whether he acted. For example, not every encounter results in offspring. If so, then a more efficient use of rewards to motivate an act of sex is to make sex directly pleasurable. But the drawback of rewarding sex directly is that whether it is desirable to have sex right now depends on how likely it is to produce valuable offspring. If we are made to care only about the (value of) offspring we are more likely to make the right decision under the right circumstances.
Now these balance out differently for males than for females. Because when the female becomes pregnant and gives birth that is a very strong signal that she had sex at an opportune time but conveys noisier information about him.That is because, of course, this child could belong to any one of her (potentially numerous) mates. Instilling a love for children is therefore a relatively more effective incentive instrument for her than for him.
As for love of sex, note that the evolutionary value of offspring is different for males than for females because females have a significant opportunity cost given that they get pregnant with one mate at a time. This means that the circumstances are nearly always right for males to have sex, but much more rarely so for females. It is therefore efficient for males to derive greater pleasure from sex.
(It is a testament to my steadfastness as a theorist that I stand firmly by the logic of this argument despite the fact that, at least in my personal experience, females derive immense pleasure from sex.)
Drawing: Misread Trajectory from www.f1me.net
How does the additional length of a 5 set match help the stronger player? Commenters to my previous post point out the direct way: it lowers the chance of a fluke in which the weaker player wins with a streak of luck. But there’s another way and it can in principle be identified in data.
To illustrate the idea, take an extreme example. Suppose that the stronger player, in addition to having a greater baseline probability of winning each set, also has the ability to raise his game to a higher level. Suppose that he can do this once in the match and (here’s the extreme part) it guarantees that he will win that set. Finally, suppose that the additional effort is costly so other things equal he would like to avoid it. When will he use his freebie?
Somewhat surprisingly, he will always wait until the last set to use it. For example, in a three set match, suppose he loses the first set. He can spend his freebie in the second set but then he has to win the third set. If he waits until the third set, his odds of winning the match are exactly the same. Either way he needs to win one set at the baseline odds.
The advantage of waiting until the third set is that this allows him to avoid spending the effort in a losing cause. If he uses his freebie in the second set, he will have wasted the effort if he loses the third set. Since the odds of winning are independent of when he spends his effort, it is unambiguously better to wait as long as possible.
This strategy has the following implications which would show up in data.
- In a five set match, the score after three sets will not be the same (statistically) as the score in a three set match.
- In particular, in a five-set match the stronger player has a lower chance of winning a third set when the match is tied 1-1 than he would in a three set match.
- The odds that a higher seeded player wins a fifth set is higher than the odds that he wins, say, the second set. (This may be hard to identify because, conditional on the match going to 5 sets, it may reveal that the stronger player is not having a good day.)
- If the baseline probability is close to 50-50, then a 5 set match can actually lower the probability that the stronger player wins, compared to a 3 set match.
This “freebie” example is extreme but the general theme would always be in effect if stronger players have a greater ability to raise their level of play. That ability is an option which can be more flexibly exercised in a longer match.
Apparently it’s biology and economics week for me because after Andrew Caplin finishes his fantastic series of lectures here at NU tomorrow, I am off to LA for this conference at USC on Biology, Neuroscience, and Economic Modeling.
Today Andrew was talking about the empirical foundations of dopamine as a reward system. Along the way he reminded us of an important finding about how dopamine actually works in the brain. It’s not what you would have guessed. If you take a monkey and do a Pavlovian experiment where you ring a bell and then later give him some goodies, the dopamine neurons fire not when the actual payoff comes, but instead when the bell rings. Interestingly, when you ring the bell and then don’t come through with the goods there is a dip in dopamine activity that seems to be associated with the letdown.
The theory is that dopamine responds to changes in expectations about payoffs, and not directly to the realization of those payoffs. This raises a very interesting theoretical question: why would that be Nature’s most convenient way to incentivize us? Think of Nature as the principal, you are the agent. You have decision-making authority because you know what choices are available and Nature gives you dopamine bonuses to guide you to good decisions. Can you come up with the right set of constraints on this moral hazard problem under which the optimal contract uses immediate rewards for the expectation of a good outcome rather than rewards that come later when the outcome actually obtains?
Here’s my lame first try, based on discount factors. Depending on your idiosyncratic circumstances your survival probability fluctuates, and this changes how much you discount the expectation of future rewards. Evolution can’t react to these changes. But if Nature is going to use future rewards to motivate your behavior today she is going to have to calibrate the magnitude of those incentive payments to your discount factor. The fluctuations in your discount factor make this prone to error. Immediate payments are better because they don’t require Nature to make any guesses about discounting.
Here is a problem at has been in the back of my mind for a long time. What is the second best dominant-strategy mechanism (DSIC) in a market setting?
For some background, start with the bilateral trade problem of Myerson-Satterthwaite. We know that among all DSIC, budget-balanced mechanisms the most efficient is a fixed-price mechanism. That is, a price is fixed ex ante and the buyer and seller simply announce whether they are willing to trade at that price. Trade occurs if and only if both are willing and if so the buyer pays the fixed price to the seller. This is Hagerty and Rogerson.
Now suppose there are two buyers and two sellers. How would a fixed-price mechanism work? We fix a price p. Buyers announce their values and sellers announce their costs. We first see if there are any trades that can be made at the fixed price p. If both buyers have values above p and both sellers have values below then both units trade at price p. If two buyers have values above p and only one seller has value below p then one unit will be sold: the buyers will compete in a second-price auction and the seller will receive p (there will be a budget surplus here.) Similarly if the sellers are on the long side they will compete to sell with the buyer paying p and again a surplus.
A fixed-price mechanism is no longer optimal. The reason is that we can now use competition among buyers and sellers and “price discovery.” A simple mechanism (but not the optimal one) is a double auction. The buyers play a second-price auction between themselves, the sellers play a second-price reverse auction between themselves. The winner of the two auctions have won the right to trade. They will trade if and only if the second highest buyer value (which is what the winning buyer will pay) exceeds the second-lowest seller value (which is what the winning seller will receive.) This ensures that there will be no deficit. There might be a surplus, which would have to be burned.
This mechanism is DSIC and never runs a deficit. It is not optimal however because it only sells one unit. But it has the viture of allowing the “price” to adjust based on “supply and demand.” Still, there is no welfare ranking between this mechanism and a fixed-price mechanism because a fixed price mechanism will sometimes trade two units (if the price was chosen fortuitously) and sometimes trade no units (if the price turned out too high or low) even though the price discovery mechanism would have traded one.
But here is a mechanism that dominates both. It’s a hybrid of the two. We fix a price p and we interleave the rules of the fixed-price mechanism and the double auction in the following order
- First check if we can clear two trades at price p. If so, do it and we are done.
- If not, then check if we can sell one unit by the double auction rules. If so, do it and we are done.
- Finally, if no trades were executed using the previous two steps then return to the fixed-price and see if we can execute a single trade using it.
I believe this mechanism is DSIC (exercise for the reader, the order of execution is crucial!). It never runs a deficit and it generates more trade than either standalone mechanism: fixed-price or double auction.
Very interesting research question: is this a second-best mechanism? If not, what is? If so, how do you generalize it to markets with an arbitrary number of buyers and sellers?
A buyer and a seller negotiating a sale price. The buyer has some privately known value and the seller has some privately known cost and with positive probability there are gains from trade but with positive probability the seller’s cost exceeds the buyers value. (So this is the Myerson-Satterthwaite setup.)
Do three treatments.
- The experimenter fixes a price in advance and the buyer and seller can only accept or reject that price. Trade occurs if and only if they both accept.
- The seller makes a take it or leave it offer.
- The parties can freely negotiate and they trade if and only if they agree on a price.
Theoretically there is no clear ranking of these three mechanisms in terms of their efficiency (the total gains from trade realized.) In practice the first mechanism clearly sacrifices some efficiency in return for simplicity and transparency. If the price is set right the first mechanism would outperform the second in terms of efficiency due to a basic market power effect. In principle the third treatment could allow the parties to find the most efficient mechanism, but it would also allow them to negotiate their way to something highly inefficient.
A conjecture would be that with a well-chosen price the first mechanism would be the most efficient in practice. That would be an interesting finding.
A variation would be to do something similar but in a public goods setting. We would again compare simple but rigid mechanisms with mechanisms that allow for more strategic behavior. For example, a version of mechanism #1 would be one in which each individual was asked to contribute an equal share of the cost and the project succeeds if and only if all agree to their contributions. Mechanism #3 would allow arbitrary negotation with the only requirement be that the total contribution exceeds the cost of the project.
In the public goods setting I would conjecture that the opposite force is at work. The scope for additional strategizing (seeding, cajoling, guilt-tripping, etc) would improve efficiency.
Anybody know if anything like these experiments have been done?
This is the third and final post on ticket pricing motivated by the new restaurant Next in Chicago and proprietors Grant Achatz and Nick Kokonas new ticket policy. In the previous two installments I tried to use standard mechanism design theory to see what comes out when you feed in some non-standard pricing motives having to do with enhancing “consumer value.” The two attempts that most naturally come to mind yielded insights but not a useful pricing system. Today the third time is the charm.
Things start to come in to place when we pay close attention to this part of Nick’s comment to us:
we never want to invert the value proposition so that customers are paying a premium that is disproportionate to the amount of food / quality of service they receive.
I propose to formalize this as follows. From the restaurant’s point of view, consumer surplus is valuable but some consumers are prepared to bid even more than the true value of the service they will get. The restaurant doesn’t count these skyscraping bids as actually reflecting consumer surplus and they don’t want to tailor their mechanism to cater to them. In particular, the restaurant distinguishes willingness to pay from “value.”
I can think of a number of sensible reasons they would take this view. They might know that many patrons overestimate the value of a seating at Next. Indeed the restaurant might worry that high prices by themselves artificially inflate willingness to pay. They don’t want a bubble. And they worry about their reputation if someone pays $1700 for a ticket, gets only $1000 worth of value and publicly gripes. Finally they might just honestly believe that willingness to pay is a poor measure of welfare especially when comparing high versus low.
Whatever the reason, let’s run with it. Let’s define 


where 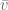

Now let’s consider the optimal pricing mechanism for a restaurant that maximizes a weighted sum of profit and consumer’s surplus, where now consumer’s surplus is measured as the difference between 

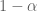
![(1 - \alpha) W(v) + (2 \alpha - 1) [v - \frac{1-F(v)}{f(v)} ]](https://s0.wp.com/latex.php?latex=%281+-+%5Calpha%29+W%28v%29+%2B+%282+%5Calpha+-+1%29+%5Bv+-+%5Cfrac%7B1-F%28v%29%7D%7Bf%28v%29%7D+%5D&bg=ffffff&fg=545454&s=0&c=20201002)
And now we have something! Because if 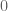
The optimal mechanism is a hybrid between an auction and a lottery. It has no reserve price (over and above the cost of service) so there are never empty seats. It earns profits but eschews exorbitant prices.
It has clear advantages over a fixed price. A fixed price is a blunt instrument that has to serve two conflicting purposes. It has to be high enough to earn sufficient revenue on dates when demand is high enough to support it, but it can’t be too high that it leads to empty seats on dates when demand is lower. An auction with rationing at the top is flexible enough to deal with both tasks independently. When demand is high the fixed price (and rationing) is in effect. When demand is low the auction takes care of adjusting the price downward to keep the restaurant full. The revenue-enhancing effects of low prices is an under-appreciated benefit of an auction. Finally, it’s an efficient allocation system for the middle range of prices so scalping motivations are reduced compared to a fixed price.
Incentives for scalping are not eliminated altogether because of the rationing at the top. This can be dealt with by controlling the resale market. Indeed here is one clear message that comes out of all of this. Whatever motivation the restaurant has for rationing sales, it is never optimal to allow unfettered resale of tickets. That only undermines what you were trying to achieve. Now Grant Achatz and Nick Kokonas understand that but they are forced to condone the Craigslist market because by law non-refundable tickets must be freely transferrable.
But the cure is worse than the disease. In fact refundable tickets are your friend. The reason someone wants to return their ticket for a refund is that their willingness to pay has dropped below the price. But there is somebody else with a willingness to pay that is above the price. We know this for sure because tickets are being rationed at that price. Granting the refund allows the restaurant to immediately re-sell it to the next guy waiting in line. Indeed, a hosted resale market would enable the restaurant to ensure that such transactions take place instantaneously through an automated system according to the same terms under which tickets were originally sold.
Someone ought to try this.
Restaurants, touring musicians, and sports franchises are not out to gouge every last penny out of their patrons. They want patrons to enjoy their craft but also to come away feeling like they didn’t pay an arm and a leg. Yesterday I tried to formalize this motivation as maximizing consumer surplus but that didn’t give a useful answer. Maximizing consumer surplus means either complete rationing (and zero profit) or going all the way to an auction (a more general argument why appears below.) So today I will try something different.
Presumably the restaurant cares about profits too. So it makes sense to study the mechanism that maximizes a weighted sum of profits and consumer’s surplus. We can do that. Standard optimal mechanism design proceeds by a sequence of mathematical tricks to derive a measure of a consumer’s value called virtual surplus. Virtual surplus allows you to treat any selling mechanism you can imagine as if it worked like this
- Consumers submit “bids”
- Based on the bids received the seller computes the virtual surplus of each consumer.
- The consumer with the highest virtual surplus is served.
If you write down the optimal mechanism design problem where the seller puts weight 

where 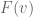
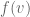
As usual, just staring down this formula tells you just about everything you want to know about how to design the pricing system. One very important thing to know is what to do when virtual surplus is a decreasing function of
But here’s a key observation: its impossible to sell to low valuation buyers and not also to high valuation buyers because whatever price the former will agree to pay the latter will pay too. So a decreasing virtual surplus means that you do the next best thing: you treat high and low value types the same. This is how rationing becomes part of an optimal mechanism.
For example, suppose the weight on profit
So that’s how we get the answer I discussed yesterday. Before going on I would like to elaborate on yesterday’s post based on correspondence I had with a few commenters, especially David Miller and Kane Sweeney. Their comments highlight two assumptions that are used to get the rationing conclusion: monotone hazard rate, and no payments to non-buyers. It gets a little more technical than usual so I am going to put it here in an addendum to yesterday (scroll down for the addendum.)
Now back to the general case we are looking at today, we can consider other values of
An important benchmark case is 
More interesting is when 

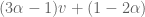
which is either decreasing over the whole range of 
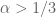
Finally when 
What do we conclude from this? Maximizing a weighted sum of consumer surplus and profit yields again yields one of two possible mechanisms: complete rationing or an auction. Neither of these mechanisms seem to fit what Nick Kokonas was looking for in his comment to us and so we have to go back to the drawing board again.
Tomorrow I will take a closer look and extract a more refined version of Nick’s objective that will in fact produce a new kind of mechanism that may just fit the bill.
Addendum: Check out these related papers by Bulow and Klemperer (dcd: glen weyl) and by Daniele Condorelli.
Last week, in response to our proposal for how to run a ticket market, Nick Kokonas of Next Restaurant wrote something interesting.
Simply, we never want to invert the value proposition so that customers are paying a premium that is disproportionate to the amount of food / quality of service they receive. Right now we have it as a great bargain for those who can buy tickets. Ideally, we keep it a great value and stay full.
Economists are not used to that kind of thinking and certainly not accustomed to putting such objectives into our models, but we should. Many sellers share Nick’s view and the economist’s job is to show the best way to achieve a principal’s objective, whatever it may be. We certainly have the tools to do it.
Here’s an interesting observation to start with. Suppose that we interpret Nick as wanting to maximize consumer surplus. What pricing mechanism does that? A fixed price has the advantage of giving high consumer surplus when willingness to pay is high. The key disadvantage is rationing: a fixed price has no way of ensuring that the guy with a high value and therefore high consumer surplus gets served ahead of a guy with a low value.
By contrast an auction always serves the guy with the highest value and that translates to higher consumer surplus at any given price. But the competition of an auction will lead to higher prices. So which effect dominates?
Here’s a little example. Suppose you have two bidders and each has a willingness to pay that is distributed according the uniform distribution on the interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)
If you use a rationing system, each bidder has a 50-50 chance of winning and paying nothing (i.e. paying the cost of service.) So a bidder whose value for service is 
If instead you use an auction, what happens? First, the highest bidder will win so that a bidder with value
However he is going to have to pay for it and his expected payment is

because when he wins his surplus is his value minus his expected payment 
So in this example we see that, from the point of view of consumer surplus, the benefits of the efficiency of an auction are more than offset by the cost of higher prices. But this is just one example and an auction is just one of many ways we could think of improving upon rationing.
However, it turns out that the best mechanism for maximizing consumer surplus is always complete rationing (I will prove this as a part of a more general demonstration tomorrow.) Set price equal to marginal cost and use a lottery (or a queue) to allocate among those willing to pay the price. (I assume that the restaurant is not going to just give away money.)
What this tells us is that maximizing consumer surplus can’t be what Nick Kokonas wants. Because with the consumer surplus maximizing mechanism, the restaurant just breaks even. And in this analysis we are leaving out all of the usual problems with rationing such as scalping, encouraging bidders with near-zero willingness to pay to submit bids, etc.
So tomorrow I will take a second stab at the question in search of a good theory of pricing that takes into account the “value proposition” motivation.
Addendum: I received comments from David Miller and Kane Sweeney that will allow me to elaborate on some details. It gets a little more technical than the rest of these posts so you might want to skip over this if you are not acquainted with the theory.
David Miller reminded me of a very interesting paper by Ran Shao and Lin Zhou. (See also this related paper by the same authors.) They demonstrate a mechanism that achieves a higher consumer surplus than the complete rationing mechanism and indeed that achieves the highest consumer surplus among all dominant-strategy, individually rational mechanisms.
Before going into the details of their mechanism let me point out the difference between the question I am posing and the one they answer. In formal terms I am imposing an additional constraint, namely that the restaurant will not give money to any consumer who does not obtain a ticket. The restaurant can give tickets away but it won’t write a check to those not lucky enough to get freebies. This is the right restriction for the restaurant application for two reasons. First if the restaurant wants to maximize consumer surplus its because it wants to make people happy about the food they eat, not happy about walking away with no food but a payday. Second, as a practical matter a mechanism that gives away money is just going to attract non-serious bidders who are looking for a handout.
In fact Shao and Zhou are starting from a related but conceptually different motivation: the classical problem of bilateral trade between two agents. In the most natural interpretation of their model the two bidders are really two agents negotiating the sale of an object that one of them already owns. Then it makes sense for one of the agents to walk away with no “ticket” but a paycheck. It means that he sold the object to the other guy.
Ok with all that background here is their mechanism in its simplest form. Agent 1 is provisionally allocated the ticket (so he becomes the seller in the bilateral negotiation.) Agent 2 is given the option to buy from agent 1 at a fixed price. If his value is above that price he buys and pays to agent 1. Otherwise agent 1 keeps the ticket and no money changes hands. (David in his comment described a symmetric version of the mechanism which you can think of as representing a random choice of who will be provisionally allocated the ticket. In our correspondence we figured out that the payment scheme for the symmetric version should be a little different, it’s an exercise to figure out how. But I didn’t let him edit his comment. Ha Ha Ha!!!)
In the uniform case the price should be set at 50 cents and this gives a total surplus of 5/8, outperforming complete rationing. Its instructive to understand how this is accomplished. As I pointed out, an auction takes away consumer surplus from high-valuation types. But in the Shao-Zhou framework there is an upside to this. Because the money extracted will be used to pay off the other agent, raising his consumer surplus. So you want to at least use some auction elements in the mechanism.
One common theme in my analysis and theirs is in fact a deep and under-appreciated result. You never want to “burn money.” Using an auction is worse than complete rationing because the screening benefits of pricing is outweighed by the surplus lost due to the payments to the seller. Using the Shao-Zhou mechanism is optimal precisely becuase it finds a clever way to redirect those payments so no money is burned. By the way this is also an important theme in David Miller’s work on dynamic mechanisms. See here and here.
Finally, we can verify that the Shao-Zhou mechanism would no longer be optimal if we adapted it to satisfy the constraint that the loser doesnt receive any money. It’s easy to do this based on the revenue equivalence theorem. In the Shao-Zhou mechanism an agent with zero value gets expected utility equal to 1/8 due to the payments he receives. We can subtract utility of 1/8 from all types and obtain an incentive-compatible mechanism with the same allocation rule. This would be just enough to satisfy my constraint. And then the total surplus will be 5/8-2/8 = 3/8 which is less than the 1/2 of the complete rationing mechanism. That’s another expression of the losses associated with using even the very crude screening in the Shao-Zhou mechanism.
Next let me tell you about my correspondence with Kane Sweeney. He constructed a simple example where an auction outperforms rationing. It works like this. Suppose that each bidder either had a very low willingness to pay, say 50 cents, or a very high willingness to pay, say $1,000. If you ration then expected surplus is about $500. Instead you could do the following. Run a second-price auction with the following modification to the rules. If both bid $1000 then toss a coin and give the ticket to the winner at a price of $1. This mechanism gives an expected surplus of about $750.
Basically this type of example shows that the monotone hazard rate assumption is important for the superiority of rationing. To see this, suppose that we smooth out the distribution of values so that types between 50 cents and $1000 have very small positive probability. Then the hazard rate is first increasing around 50 cents and then decreasing from 50 cents all the way to $1000. So you want to pool all the types above 50 cents but you want to screen out the 50-cent types. That’s what Kane’s mechanism is doing.
I would interpret Kane’s mechanism as delivering a slightly nuanced version of the rationing message. You want to screen out the non-serious bidders but ration among all of the serious bidders.

I am always writing about athletics from the strategic point of view: focusing on the tradeoffs. One tradeoff in sports that lends itself to strategic analysis is effort vs performance. When do you spend the effort to raise your level of play and rise to the occasion?
My posts on those subjects attract a lot of skeptics. They doubt that professional athletes do anything less than giving 100% effort. And if they are always giving 100% effort, then the outcome of a contest is just determined by gourd-given talent and random factors. Game theory would have nothing to say.
We can settle this debate. I can think of a number of smoking guns to be found in data that would prove that, even at the highest levels, athletes vary their level of performance to conserve effort; sometimes trying hard and sometimes trying less hard.
Here is a simple model that would generate empirical predictions. Its a model of a race. The contestants continuously adjust how much effort to spend to run, swim, bike, etc. to the finish line. They want to maximize their chance of winning the race, but they also want to spend as little effort as necessary. So far, straightforward. But here is the key ingredient in the model: the contestants are looking forward when they race.
What that means is at any moment in the race, the strategic situation is different for the guy who is currently leading compared to the trailers. The trailer can see how much ground he needs to make up but the leader can’t see the size of his lead.
If my skeptics are right and the racers are always exerting maximal effort, then there will be no systematic difference in a given racer’s time when he is in the lead versus when he is trailing. Any differences would be due only to random factors like the racing conditions, what he had for breakfast that day, etc.
But if racers are trading off effort and performance, then we would have some simple implications that, if it were born out in data, would reject the skeptics’ hypothesis. The most basic prediction follows from the fact that the trailer will adjust his effort according to the information he has that the leader does not have. The trailer will speed up when he is close and he will slack off when he has no chance.
In terms of data the simplest implication is that the variance of times for a racer when he is trailing will be greater than when he is in the lead. And more sophisticated predictions would follow. For example the speed of a trailer would vary systematically with the size of the gap while the speed of a leader would not.
The results from time trials (isolated performance where the only thing that matters is time) would be different from results in head-to-head competitions. The results in sequenced competitions, like downhill skiing, would vary depending on whether the racer went first (in ignorance of the times to beat) or last.
And here’s my favorite: swimming races are unique because there is a brief moment when the leader gets to see the competition: at the turn. This would mean that there would be a systematic difference in effort spent on the return lap compared to the first lap, and this would vary depending on whether the swimmer is leading or trailing and with the size of the lead.
And all of that would be different for freestyle races compared to backstroke (where the leader can see behind him.)
Finally, it might even be possible to formulate a structural model of an effort/performance race and estimate it with data. (I am still on a quest to find an empirically oriented co-author who will take my ideas seriously enough to partner with me on a project like this.)
Drawing: Because Its There from www.f1me.net

Suppose I want you to believe something and after hearing what I say you can, at some cost, check whether I am telling the truth. When will you take my word for it and when will you investigate?
If you believe that I am someone who always tells the truth you will never spend the cost to verify. But then I will always lie (whenever necessary.) So you must assign some minimal probability to the event that I am a liar in order to have an incentive to investigate and keep me in check.
Now suppose I have different ways to frame my arguments. I can use plain language or I can cloak them in the appearance of credibility by using sophisticated jargon. If you lend credibility to jargon that sounds smart, then other things equal you have less incentive to spend the effort to verify what I say. That means that jargon-laden statements must be even more likely to be lies in order to restore the balance.
(Hence, statistics come after “damned lies” in the hierarchy.)
Finally, suppose that I am talking to the masses. Any one of you can privately verify my arguments. But now you have a second, less perfect way of checking. If you look around and see that a lot of other people believe me, then my statements are more credible. That’s because if other people are checking me and many of them demonstrate with their allegiance that they believe me, it reveals that my statements checked out with those that investigated.
Other things equal, this makes my statements more credible to you ex ante and lowers your incentives to do the investigating. But that’s true of everyone so there will be a lot of free-riding and too little investigating. Statements made to the masses must be even more likely to be lies to overcome that effect.
Drawing: Management Style II: See What Sticks from www.f1me.net
Almost every kind of race works like this: we agree on a distance and we see who can complete that distance in the shortest time. But that is not the only way to test who is the fastest. The most obvious alternative is to switch the roles of the two variables: fix a time and see who can go the farthest in that span of time.
Once you think of that the next question to ask is, does it matter? That is, if the purpose of the race is to generate a ranking of the contestants (first place, second place, etc) then are there rankings that can be generated using a fixed-time race that cannot be replicated using an appropriately chosen fixed-distance race?
I thought about this and here is a simple way to formalize the question. Below I have represented three racers. A racer is characterized by a curve which shows for every distance how long it takes him to complete that distance.

Now a race can be represented in the same diagram. For example, a standard fixed-distance race looks like this.

The vertical line indicates the distance and we can see that Green completes that distance in the shortest time, followed by Black and then Blue. So this race generates the ranking Green>Black>Blue. A fixed-time race looks like a horizontal line:

To determine the ranking generated by a fixed-time race we move from right to left along the horizontal line. In this time span, Black runs the farthest followed by Green and then Blue.
(You may wonder if we can use the same curve for a fixed-time race. After all, if the racers are trying to go as far as possible in a given length of time they would adjust their strategies accordingly. But in fact the exact same curve applies. To see this suppose that Blue finishes a d-distance race in t seconds. Then d must be the farthest he can run in t seconds. Because if he could run any farther than d, then it would follow that he can complete d in less time than t seconds. This is known as duality by the people who love to use the word duality.)
OK, now we ask the question. Take an arbitrary fixed-time race, i.e. a horizontal line, and the ordering it generates. Can we find a fixed-distance race, i.e. a vertical line that generates the same ordering? And it is easy to see that, with 3 racers, this is always possible. Look at this picture:

To find the fixed-distance race that would generate the same ordering as a given fixed-time race, we go to the racer who would take second place (here that is Black) and we find the distance he completes in our fixed-time race. A race to complete that distance in the shortest time will generate exactly the same ordering of the contestants. This is illustrated for a specific race in the diagram but it is easy to see that this method always works.
However, it turns out that these two varieties of races are no longer equivalent once we have more than 3 racers. For example, suppose we add the Red racer below.

And consider the fixed-time race shown by the horizontal line in the picture. This race generates the ordering Black>Green>Blue>Red. If you study the picture you will see that it is impossible to generate that ordering by any vertical line. Indeed, at any distance where Blue comes out ahead of Red, the Green racer will be the overall winner.
Likewise, the ordering Green>Black>Red>Blue which is generated by the fixed-distance race in the picture cannot be generated by any fixed-time race.
So, what does this mean?
- The choice of race format is not innocuous. The possible outcomes of the race are partially predetermined what would appear to be just arbitrary units of measurement. (Indeed I would be a world class sprinter if not for the blind adherence to fixed-distance racing.)
- There are even more types of races to consider. For example, consider a ray (or any curve) drawn from the origin. That defines a race if we order the racers by the first point they cross the curve from below. One way to interpret such a race is that there is a pace car on the track with the racers and a racer is eliminated as soon as he is passed by the pace car. If you play around with it you will see that these races can also generate new orderings that cannot be duplicated. (We may need an assumption here because duality by itself may not be enough, I don’t know.)
- That raises a question which is possibly even a publishable research project: What is a minimal set of races that spans all possible races? That is, find a minimal set of races such that if there is any group of contestants and any race (inside or outside the minimal set) that generates some ordering of those contestants then there is a race in the set which generates the same ordering.
- There are of course contests that are time based rather than quantity based. For example, hot dog eating contests. So another question is, if you have to pick a format, then which kinds of feats better lend themselves to quantity competition and which to duration competition?

I wrote last week about More Guns, Less Crime. That was the theory, let’s talk about the rhetoric.
Public debates have the tendency to focus on a single dimension of an issue with both sides putting all their weight behind arguments on that single front. In the utilitarian debate about the right to carry concealed weapons, the focus is on More Guns, Less Crime. As I tried to argue before, I expect that this will be a lost cause for gun control advocates. There just isn’t much theoretical reason why liberalized gun carry laws should increase crime. And when this debate is settled, it will be a victory for gun advocates and it will lead to a discrete drop in momentum for gun control (that may have already happened.)
And that will be true despite the fact that the real underlying issue is not whether you can reduce crime (after all there are plenty of ways to do that,) but at what cost. And once the main front is lost, it will be too late for fresh arguments about externalities to have much force in public opinion. Indeed, for gun advocates the debate could not be more fortuitously framed if the agenda were set by a skilled debater. A skilled debater knows the rhetorical value of getting your opponent to mount a defense and thereby implicitly cede the importance of a point, and then overwhelming his argument on that point.
Why do debates on inherently multi-dimensional issues tend to align themselves so neatly on one axis? And given that they do, why does the side that’s going to lose on those grounds play along? I have a theory.
Debate is not about convincing your opponent but about mobilizing the spectators. And convincing the spectators is neither necessary nor sufficient for gaining momentum in public opinion. To convince is to bring others to your side. To mobilize is to give your supporters reason to keep putting energy into the debate.
The incentive to be active in the debate is multiplied when the action of your supporters is coordinated and when the coordination among opposition is disrupted. Coordinated action is fueled not by knowledge that you are winning the debate but by common knowledge that you are winning the debate. If gun control advocates watch the news after the latest mass killing and see that nobody is seriously representing their views, they will infer they are in the minority and give up the fight even if in fact they are in the majority.
Common knowledge is produced when a publicly observable bright line is passed. Once that single dimension takes hold in the public debate it becomes the bright line: When the dust is settled it will be common knowledge who won. A second round is highly unlikely because the winning side will be galvanized and the losing side demoralized. Sure there will be many people, maybe even most, who know that this particular issue is of secondary importance but that will not be common knowledge. So the only thing to do is to mount your best offense on that single dimension and hope for a miracle or at least to confuse the issue.
(Real research idea for the vapor mill. Conjecture: When x and y are random variables it is “easier” to generate common knowledge that x>0 than to generate common knowledge that x>y.)
Chickle: Which One Are You Talking About? from www.f1me.net.
Believe it or not that line of thinking does lie just below the surface in many recruiting discussions. The recruiting committee wants to hire good people but because the market moves quickly it has to make many simultaneous offers and runs the risk of having too many acceptances. There is very often a real feeling that it is safe to make offers to the top people who will come with low probability but that its a real risk to make an offer to someone for whom the competition is not as strong and who is therefore likely to accept.
This is not about adverse selection or the winner’s curse. Slot-constraint considerations appear at the stage where it has already been decided which candidates we like and all that is left is to decide which ones we should offer. Anybody who has been involved in recruiting decisions has had to grapple with this conundrum.
But it really is a phantom issue. It’s just not possible to construct a plausible model under which your willingness to make an offer to a candidate is decreasing in the probability she will come. Take any model in which there is a (possibly increasing) marginal cost of filling a slot and candidates are identified by their marginal value and the probability they would accept an offer.
Consider any portfolio of offers which involves making an offer to candidate F. The value of that portfolio is a linear function of the probability that F accepts the offer. For example, consider making offers to two candidates 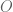
![q_O [ q_F (v_F +v_O - C(2))+( 1 - q_F )(v_O - C(1) ) ]](https://s0.wp.com/latex.php?latex=q_O+%5B+q_F+%28v_F+%2Bv_O+-+C%282%29%29%2B%28+1+-+q_F+%29%28v_O+-+C%281%29+%29+%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![+(1 -q_O)[q_F v_F-C(1)]](https://s0.wp.com/latex.php?latex=%2B%281+-q_O%29%5Bq_F+v_F-C%281%29%5D&bg=ffffff&fg=545454&s=0&c=20201002)
where 




![q_F \left[q_O\left(v_F-MC(2)\right)+(1- q_O) \left(v_F - C(1)\right) \right] + const.](https://s0.wp.com/latex.php?latex=q_F+%5Cleft%5Bq_O%5Cleft%28v_F-MC%282%29%5Cright%29%2B%281-+q_O%29+%5Cleft%28v_F+-+C%281%29%5Cright%29+%5Cright%5D+%2B+const.&bg=ffffff&fg=545454&s=0&c=20201002)
where 
In particular, if
It’s not to say that there aren’t interesting portfolio issues involved in this problem. One issue is that worse candidates can crowd out better ones. In the example, as the probability that
For example, suppose that the department is slot-constrained and would incur the Dean’s wrath if it hired two people this year. If 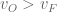
In general, I guess that the optimal portfolio is a hard problem to solve. It reminds me of this paper by Hector Chade and Lones Smith. They study the problem of how many schools to apply to, but the analysis is related.
What is probably really going on when the titular quotation arises is that factions within the department disagree about the relative values of
Another observation is that Deans should not use hard offer constraints but instead expose the department to the true marginal cost curve, understanding that the department will make these calculations and voluntarily ration offers on its own. (When

By asking a hand-picked team of 3 or 4 experts in the field (the “peers”), journals hope to accept the good stuff, filter out the rubbish, and improve the not-quite-good-enough papers.
…Overall, they found a reliability coefficient (r^2) of 0.23, or 0.34 under a different statistical model. This is pretty low, given that 0 is random chance, while a perfect correlation would be 1.0. Using another measure of IRR, Cohen’s kappa, they found a reliability of 0.17. That means that peer reviewers only agreed on 17% more manuscripts than they would by chance alone.
That’s from neuroskeptic writing about an article that studies the peer-review process. I couldn’t tell you what Cohen’s kappa means but let’s just take the results at face value: referees disagree a lot. Is that bad news for peer-review?
Suppose that you are thinking about whether to go to a movie and you have three friends who have already seen it. You must choose in advance one or two of them to ask for a recommendation. Then after hearing their recommendation you will decide whether to see the movie.
You might decide to ask just one friend. If you do it will certainly be the case that sometimes she says thumbs-up and sometimes she says thumbs-down. But let’s be clear why. I am not assuming that your friends are unpredictable in their opinions. Indeed you may know their tastes very well. What I am saying is rather that, if you decide to ask this friend for her opinion, it must be because you don’t know it already. That is, prior to asking you cannot predict whether or not she will recommend this particular movie. Otherwise, what is the point of asking?
Now you might ask two friends for their opinions. If you do, then it must be the case that the second friend will often disagree with the first friend. Again, I am not assuming that your friends are inherently opposed in their views of movies. They may very well have similar tastes. After all they are both your friends. But, you would not bother soliciting the second opinion if you knew in advance that it was very likely to agree or disagree with the first on this particular movie. Because if you knew that then all you would have to do is ask the first friend and use her answer to infer what the second opinion would have been.
If the two referees you consult are likely to agree one way or the other, you get more information by instead dropping one of them and bringing in your third friend, assuming he is less likely to agree.
This is all to say that disagreement is not evidence that peer-review is broken. Exactly the opposite: it is a sign that editors are doing a good job picking referees and thereby making the best use of the peer-review process.
It would be very interesting to formalize this model, derive some testable implications, and bring it to data. Good data are surely easily accessible.
(Picture: Right Sizing from www.f1me.net)

You go around saying X. There are some people who agree with X and others who disagree. Those who agree with X don’t blink an eye when you say X. Those who disagree with X tell you X is wrong.
At some point you have to rethink whether you agree with X. You have a bunch of definitive signals against X but the signals in favor of X are hard to count. You have to count the number of times people didn’t say anything about X. You are naturally biased against X.
Eventually you change your mind and go around saying not-X. Repeat.
Here’s a broad class of games that captures a typical form of competition. You and a rival simultaneously choose how much effort to spend and depending on your choices, you earn a score, a continuous variable. The score is increasing in your effort and decreasing in your rival’s effort. Your payoff is increasing in your score and decreasing in your effort. Your rival’s payoff is decreasing in your score and his effort.
In football, this could model an individual play where the score is the number of yards gained. A model like this gives qualitatively different predictions when the payoff is a smooth function of the score versus when there are jumps in the payoff function. For example, suppose that it is 3rd down and 5 yards to go. Then the payoff increases gradually in the number of yards you gain but then jumps up discretely if you can gain at least 5 yards giving you a first down. Your rival’s payoff exhibits a jump down at that point.
If it is 3rd down and 20 then that payoff jump requires a much higher score. This is the easy case to analyze because the jump is too remote to play a significant role in strategy. The solution will be characterized by a local optimality condition. Your effort is chosen to equate the marginal cost of effort to the marginal increase in score, given your rival’s effort. Your rival solves an analogous problem. This yields an equilibrium score strictly less than 20. (A richer, and more realistic model would have randomness in the score.) In this equilibrium it is possible for you to increase your score, even possibly to 20, but the cost of doing so in terms of increased effort is too large to be profitable.
Suppose that in the above equilibrium you gain 4 yards. Then when it is 3rd down and 5 this equilibrium will unravel. The reason is that although the local optimality condition still holds, you now have a profitable global deviation, namely putting in enough effort to gain 5 yards. That deviation was possible before but unprofitable because 5 yards wasn’t worth much more than 4. Now it is.
Of course it will not be an equilibrium for you to gain 5 yards because then your opponent can increase effort and reduce the score below 5 again. If so, then you are wasting the extra effort and you will reduce it back to the old value. But then so will he, etc. Now equilibrium requires mixing.
Finally, suppose it is 3rd down and inches. Then we are back to a case where we don’t need mixing. Because no matter how much effort your opponent uses you cannot be deterred from putting in enough effort to gain those inches.
The pattern of predictions is thus: randomness in your strategy is non-monotonic in the number of yards needed for a first down. With a few yards to go strategy is predictable, with a moderate number of yards to go there is maximal randomness, and then with many yards to go, strategy is predictable again. Variance in the number of yards gained in these cases will exhibit a similar non-monotonicity.
This could be tested using football data, with run vs. pass mix being a proxy for randomness in strategy.
While we are on the subject, here is my Super Bowl tweet.

Tennis commentators will typically say about a tall player like John Isner or Marin Cilic that their height is a disadvantage because it makes them slow around the court. Tall players don’t move as well and they are not as speedy.
On the other hand, every year in my daughter’s soccer league the fastest and most skilled player is also among the tallest. And most NBA players of Isner’s height have no trouble keeping up with the rest of the league. Indeed many are faster and more agile than Isner. LeBron James is 6’8″.
It is not true that being tall makes you slow. Agility scales just fine with height and it’s a reasonable assumption that agility and height are independently distributed in the population. Nevertheless it is true in practice that all of the tallest tennis players on the tour are slower around the court.
But all of these facts are easily reconcilable. In the tennis production function, speed and height are substitutes. If you are tall you have an advantage in serving and this can compensate for lower than average speed if you are unlucky enough to have gotten a bad draw on that dimension. So if we rank players in terms of some overall measure of effectiveness and plot the (height, speed) combinations that produce a fixed level of effectiveness, those indifference curves slope downward.
When you are selecting the best players from a large population, the top players will be clustered around the indifference curve corresponding to “ridiculously good.” And so when you plot the (height, speed) bundles they represent, you will have something resembling a downward sloping curve. The taller ones will be slower than the average ridiculously good tennis player.
On the other hand, when you are drawing from the pool of Greater Winnetka Second Graders with the only screening being “do their parent cherish the hour per week of peace and quiet at home while some other parent chases them around?” you will plot an amorphous cloud. The best player will be the one farthest to the northeast, i.e. tallest and fastest.
Finally, when the sport in question is one in which you are utterly ineffective unless you are within 6 inches of the statistical upper bound in height, then a) within that range height differences matter much less in terms of effectiveness so that height is less a substitute for speed at the margin and b) the height distribution is so compressed that tradeoffs (which surely are there) are less stark. Mugsy Bogues notwithstanding.

In sports, high-powered incentives separate the clutch performers from the chokers. At least that’s the usual narrative but can we really measure clutch performance? There’s always a missing counterfactual. We say that he chokes if he doesn’t come through when the stakes are raised. But how do we know that he wouldnt have failed just as miserably under normal circumstances? As long as performance has a random element, pure luck (good or bad) can appear as if it were caused by circumstances.
You could try a controlled experiment, and probably psychologists have. But there is the usual leap of faith required to extrapolate from experimental subjects in artificial environments to professionals trained and selected for high-stakes performance.
Here is a simple quasi-experiment that could be done with readily available data. In basketball when a team accumulates more than 5 fouls, each additional foul sends the opponent to the free-throw line. This is called the “bonus.” In college basketball the bonus has two levels. After fouls 5-10 (correction: fouls 7-9) the penalty is what’s called a “one and one.” One free-throw is awarded, and then a second free-throw is awarded only if the first one is good. After 10 fouls the team enters the “double bonus” where the shooter is awarded two shots no matter what happens on the first. (In the NBA there is no “single bonus,” after 5 fouls the penalty is two shots.)
The “front end” of the one-and-one is a higher stakes shot because the gain from making it is 1+p points where p is the probability of making the second. By contrast the gain from making the first of two free throws is just 1 point. On all other dimensions these are perfectly equivalent scenarios, and it is the most highly controlled scenario in basketball.
The clutch performance hypothesis would imply that success rates on the front end of a one and one are larger than success rates on the first free-throw out of two. The choke-under-pressure hypothesis would imply the opposite. It would be very interesting to see the data.
And if there was a difference, the next thing to do would be to analyze video to look for differences in how players approach these shots. For example I would bet that there is a measurable difference in the time spent preparing for the shot. If so, then in the case of choking the player is “overthinking” and in the clutch case this would provide support for an effort-performance tradeoff.

For 4.6 billion years, the Sun has provided free energy, light, and warmth to Earth, and no one ever realized what a huge moneymaking opportunity is going to waste. Well, at long last, the Sun is finally under new ownership.
Angeles Duran, a woman from the Spanish region of Galicia, is the new proud owner of the Sun. She says she got the idea in September when she read about an American man registering his ownership of the Moon and most of the planets in the Solar System – in other words, all the celestial bodies that don’t actually do anything for us.
Duran, on the other hand, snapped up the solar system’s powerhouse, and all it cost her was a trip down to the local notary public to register her claim. She says that she has every right do this within international law, which only forbids countries from claiming planets or stars, not individuals:
“There was no snag, I backed my claim legally, I am not stupid, I know the law. I did it but anyone else could have done it, it simply occurred to me first.”
She will soon begin charging for use. I advise her to hire a good consultant because pricing The Sun is not your run-of-the-mill profit maximization exercise. First of all, The Sun is a public good. No individual Earthling’s willingness to pay incorporates the total social value created by his purchase. So it’s going to be hard to capitalize on the true market value of your product even if you could get 100% market share.
Even worse, its a non-excludable public good. Which means you have to cope with a massive free-rider problem. As long as one of us pays for it, you turn it on, we all get to use it. So if you just set a price for The Sun, forget about market share, at most your gonna sell to just one of us.
You have to use a more sophisticated mechanism. Essentially you make the people of Earth play a game in which they all pledge individual contributions and you commit not to turn on The Sun unless the total pledge exceeds some minimum level. You are trying to make each individual feel as if his pledge has a chance of being pivotal: if he doesn’t contribute today then The Sun doesn’t rise tomorrow.
A mechanism like that will do better than just hanging a simple price tag on The Sun but don’t expect a windfall even from the best possible mechanism. Mailath and Postlewaite showed, essentially, that the maximum per-capita revenue you can earn from selling The Sun converges to zero as the population increases due to the ever-worsening free-rider problem.
You might want to start looking around for other planets in need of a yellow dwarf and try to generate a little more competition.
(Actual research comment: Mailath and Postlewaite consider efficient public good provision. I am not aware of any characterization of the profit-maximizing mechanism for a fixed population size and zero marginal production cost.)
[drawing: Move Mountains from http://www.f1me.net]

Why do we get more conservative (little ‘c’) as we get older? Trying out new things pays off less when there’s less time left to benefit from the upside. That’s a simple story based on declining patience.
But there’s another reason which could kick in at middle age when there is still plenty of life left to live. Think of life as a sequence of gambles presented to you. They come with labels: gamble A, gamble B, …, etc. Every time you get the chance to try gamble A its a draw from the same distribution and you get more information about gamble A.
Suppose your memory is limited. What you can remember is some list of gambles that you currently believe are worth taking. When you have the opportunity to take a gamble that is on the list, you take it. When you are presented with a gamble that is not on the list you have a decision to make. You could try it, and if it looks good you can put it on your list but then you have to drop something else from your list. Or you can pass.
As time goes on, even though you don’t remember everything you once tried and then removed from your list, you know that there must have been a lot of those. And so when you are presented with an option that is truly new, you have no way of knowing that and your best guess is that you have actually tried it before and discarded it. So you pass.
(drawing: Stuck In Your Head from f1me.)

Because communication requires both a talker and a listener and it takes time and energy for the listener to process information. So it may be cheap to talk but it is costly to listen.
But then the cost of listening implies that there is an opportunity cost to everything you say. Because you can only say so much and still be listened to. They won’t drink from a firehose.
When you want to be listened to you have an incentive to ration what you say, and therefore the mere fact that you chose to say something conveys information about how valuable it was to you to have it heard. There is no babbling because babbling isn’t worth it.
I also believe that this is a key friction determining the architecture of social networks. Who talks and who listens to whom? The efficient structure economizes on the cost of listening. It is efficient to have a small number of people who specialize in listening to many sources then selectively “curating” and rebroadcasting specialized content. End-listeners are spared the cost of filtering. The economic question is whether the private and social incentives are aligned for someone who must ration his output in order to attract listeners.
The threat of the death penalty makes defendants more willing to accept a given plea bargain offer. But a tough-on-crime DA takes up the slack by making tougher offers. What is the net effect? A simple model delivers a clear prediction: the threat of the death penalty results in fewer plea bargains and more cases going to trial.
The DA is like a textbook monopolist but instead of setting a price, he offers a reduced sentence. The defendant can accept the offer and plead guilty or reject and go to trial taking his chances with the jury. Just like the monopolist, the DA’s optimal plea offer trades off marginal benefit and marginal cost. When he offers a stiffer sentence, the marginal benefit is that defendants who accept it serve more time. The marginal cost is that it is more likely that the defendant rejects the tougher offer, and more cases goes to trial. The marginal defendant is the one whose trial prospects make him just indifferent between accepting and rejecting the plea bargain.
Introducing the death penalty changes the payoff to a defendant who rejects a plea deal (his reservation value.) The key observation is that this change affects defendants differently according to their likelihood of conviction at trial. Defendants facing a difficult case are more likely to be convicted and suffer the increased penalty. (Formally, the reservation value is now steeper as a function of the probability of conviction.)
One thing the DA could do is increase the sentence in his plea bargain offer just enough that the pre-death-penalty marginal defendant is once again indifferent between accepting and rejecting. The rate of plea bargains would then be the same as before the death penalty.
But he can do better by offering an even tougher sentence. The reason: his marginal benefit of such a move is the same as it was pre-death penalty (the same infra-marginal defendants serve more time) but the marginal cost is now lower for two reasons. First, compared to the no-death penalty scenario, fewer defendants reject the tougher offer. Because we are moving along a steeper reservation value curve. Second, those who do reject now get a stiffer penalty (death) conditional on conviction.
The DA’s tougher stance in plea bargaining means that fewer defendants accept and more cases go to trial. Evidence? Here is one paper that shows that re-instatement of the death penalty in New York lead to no increase in the rate of plea bargains accepted (and a clear decrease in the size of plea bargain offers.)
Suppose I want to divide a pie between you and another person. It is known that the other person would get value 
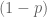


My goal is to allocate the pie efficiently. If both of you are selfish, then this means that I would like to give all the pie to him if 
But what if you are inequity averse? Inequity aversion is a behavioral theory of preferences which is often used to explain non-selfish behavior that we see in experiments. If you are inequity averse your utility has a kink at the point where your total pie value equals his. When you have less than him you always like more pie both because you like pie and because you dislike the inequality. When you have more than him you are conflicted because you like more pie but you dislike having even more than he has.
In that case, my objective is more interesting than when you are selfish. If
And its now much easier to get you to tell me the truth. You will always tell me the truth when your value of
So inequity aversion has a very clear implication for an experiment like this. If the experimenter is promising always to divide the pie equitably and is asking the subject to report his value of
I would be curious to see if there are any experiments like this.
I am looking for a Northwestern student who can help me with a very small data collection task. PhD student preferred. It wouldn’t take more than a few hours and I would pay you the standard RA rate plus eventual fame and glory.

{kind=link}