
You are currently browsing the tag archive for the ‘vapor mill’ tag.
Here is an article on the latest Michelin stars for Chicago Restaurants. The very nice thing about this article is that it tells you which restaurants just missed getting a star. As of yesterday you would have preferred the now-starred restaurants over the now-snubbed restaurants. But probably as of today that preference is reversed.
Any punishment designed for deterrence is based on the following calculation. The potential criminal weighs the benefit of the crime against the cost, where the cost is equal to the probability of being caught multiplied by the punishment if caught.
Taking surveillance technology as given, the punishment is set in order to calibrate the right-hand-side of that comparison. Optimally, the expected punishment equals the marginal social cost of the crime so that crimes whose marginal social cost outweighs the marginal benefit are deterred.
When technology allows improved surveillance, the law does not adjust automatically to keep the right-hand side constant. Indeed there is a ratchet effect in criminal law: penalties never go down.
So we naturally hate increased surveillance, even those of us who would welcome it in a first-best world where punishments adjust along with technology.
Suppose there’s a precedent that people don’t like. A case comes up and they are debating whether the precedent applies. Often the most effective way to argue against it is to cite previous cases where the precedent was applied and argue that the present case is different.
In order to maximally differentiate the current case they will exaggerate how appropriate the precedent was to the specific details of the previous case, even though they disagree with the precedent in principle because that case was already decided and nothing can be done about that now.
The long run effect of this is to solidify those cases as being good examples where the precedent applies and thereby solidify the precedent itself.
Suppose you are writing a referee report and you are recommending that the paper be rejected. You have a long list of reasons. How many should you put in your report? If you put only your few strongest arguments you run the risk that the author (or editor) finds a response to those and accepts the paper.
You will have lost the chance to use your next few strongest arguments to their full effect, even if there is a second round. The reason has to do with a basic friction of rhetoric. Nobody really knows what’s true or false, but the more you’ve thought about it the better informed you are. So there is always a signaling aspect to rhetoric. Even if the opponent can’t find a counterargument, when it is known that you rank your argument low in terms of persuasiveness, your argument will as a result be in fact less persuasive. Your ranking reveals that you believe that the probability is high that a counterargument could be found, even if by chance this time it wasn’t.
On the other hand you also don’t want to put all of your arguments down. The risk here is that the author refutes all but your strongest one or two arguments. Then the editor may conclude that your decision to reject was made on the basis of that long list of considerations and now that a large percentage of them have been refuted this seals the case in favor. Had you left out all the weak arguments your case would look stronger.
It may even be optimal to pick a non-interval subset of arguments. That is you might give your strongest argument, leave out the second strongest but include the third strongest. The reason is that you care not just about the probability that any single one of your arguments is refuted but the probability that a large subset of your arguments survive. And here correlation matters. It may be that a refutation of the strongest argument is likely also to partially weaken the second-strongest. You pick the third because it is orthogonal to the first.
Suppose you and a friend of the opposite sex are recruited for an experiment. You are brought into separate rooms and told that you will be asked some questions and, unless you give consent, all of your answers will be kept secret.
First you are asked whether you would like to hook up with your friend. Then you are asked whether you believe your friend would like to hook up with you. These are just setup questions. Now come the important ones. Assuming your friend would like to hook up with you, would you like to know that? Assuming your friend is not interested, would you like to know that? And would you like your friend to know that you know?
Assuming your friend is interested, would you like your friend to know whether you are interested? Assuming your friend is not interested, same question. And the higher-order question as well.
These questions are eliciting your preferences over you and your friend’s beliefs about (beliefs about…) you and your friend’s preferences. This is one context where the value of information is not just instrumental (i.e. it helps you make better decisions) but truly intrinsic. For example I would guess that for most people, if they are interested and they know that the other is not that they would strictly prefer that the other not know that they are interested. Because that would be embarrassing.
And I bet that if you are not interested and you know that the other is interested you would not like the other to know that you know that she is interested. Because that would be awkward.
Notice in fact that there is often a strict preference for less information. And that’s what makes the design of a matching mechanism complicated. Because in order to find matches (i.e. discover and reveal mutual interest) you must commit to reveal the good news. In other words, if you and your friend both inform the experimenters that you are interested and that you want the other to know that, then in order to capitalize on the opportunity the information must be revealed.
But any mechanism which reveals the good news unavoidably reveals some bad news precisely when the good news is not forthcoming. If you are interested and you want to know when she is interested and you expect that whenever she is indeed interested you will get your wish, then when you don’t get your wish you find out that she is not interested.
Fortunately though there is a way to minimize the embarrassment. The following simple mechanism does pretty well. Both friends tell the mediator whether they are interested. If, and only if, both are interested the mediator informs both that there is a mutual interest. Now when you get the bad news you know that she has learned nothing about your interest. So you are not embarrassed.
However it doesn’t completely get rid of the awkwardness. When she is not interested she knows that *if* you are interested you have learned that she is not interested. Now she doesn’t know that this state of affairs has occurred for sure. She thinks it has occurred if and only if you are interested so she thinks it has occurred with some moderate probability. So it is moderately awkward. And indeed you know that she is not interested and therefore feels moderately awkward.
The theoretical questions are these: under what specification of preferences over higher-order beliefs over preferences is the above mechanism optimal? Is there some natural specification of those preferences in which some other mechanism does better?
Update: Ran Spiegler points me to this related paper.
[audio http://www.kellogg.northwestern.edu/podcasts/insight/baliga/sandeep092013.mp3]
We were interviewed by the excellent Jessica Love for Kellogg Insight. Its about 12 minutes long. Here’s one bit I liked:
We go around in our lives and we collect information about what we should do, what we should believe and really all that matters after we collect that information is the beliefs that we derive from them and its hard to keep track of all the things we learn in our lives and most of them are irrelevant once we have accounted for them in our beliefs, the particular pieces of information we can forget as long as we remember what beliefs we should have. And so a lot of times what we are left with after this is done are beliefs that we feel very strongly about and someone comes and interrogates us about what’s the basis of our beliefs and we can’t really explain it and we probably can’t convince them and they say, well you have these irrational beliefs. But its really just an optimization that we’re doing, collecting information, forming our beliefs and then saving our precious memory by discarding all of the details.
I wish I could formalize that.
The NRA successfully lobbied to stop gun control legislation. Several Democrats sided with Republicans to defeat it. But the NRA seems to have spent more than necessary to defeat the measures because they failed by more than a one-vote margin. It would have been enough to buy exactly the number of Senators necessary to prevent the bill from progressing through the Senate, no more than that.
But in fact the cost of defeating legislation is decreasing in the number of excess votes purchased. If the NRA has already secured enough votes to win, the next vote cannot be pivotal and so the Senator casting that vote takes less blame for the defeat. Indeed if enough Senators are bought so that the bill goes down by at least two votes, no Senator is pivotal.
Here’s a simple model. Suppose that the political cost of failing to pass gun control is c. If the NRA buys the minimum number of votes needed to halt the legislation it must pay c to each Senator it buys. That’s because each of those Senators could refuse to vote for the NRA and avoid the cost c. But if the NRA buys one extra vote, each Senator incurs the cost c whether or not he goes along with the NRA and his vote has just become cheaper by the amount c.
For the Vapor Mill: What is the voting rule that maximizes the cost of defeating popular legislation?
NEWRY, Maine — A Finnish couple has added to their victories by taking first place in the North American Wife Carrying Championship at Maine’s Sunday River ski resort.
Taisto Miettinen and Kristina Haapanen traveled from Helsinki, Finland – where they won the World Wife Carrying Championship – for Saturday’s contest. The Sun Journal (bit.ly/Q30QWq) reports that the couple finished with a time of 52.58 seconds on a course that includes hurdles, sand traps and a water hole.
The winners receive the woman’s weight in beer and five times her weight in cash.
The model: At date 0 each of N husbands decides how fat his wife should be. At date 1 they run a wife-carrying race, where the husband’s speed is given by some function f(s,w) where s is the strength of the husband, and w is the weight of his wife. The function f is increasing in its first argument and decreasing in the second. The winner gets K times his wife’s weight in cash and beer. Questions
- If the husbands are symmetric what is the equilibrium distribution of wife weights?
- Under what conditions on f does a stronger husband have a fatter wife?
- Derive the comparative statics with respect to K.

Here’s a thought I had over a lunch of Mee Goreng and Rojak. As the cost of transportation declines there is a non-monotonic effect on migration. Decreasing transportation costs make it cheaper to visit and discover new places. But for small cost reductions it is still too costly to visit frequently. So if you find a place you like you must migrate there.
For large declines in transportation costs, it becomes cheap to frequently visit the places that you like and you would otherwise want to migrate to. So migration declines.
The same non-monotonic effect can be seen as a function of distance. For any given decline in transportation costs migration to far away destinations increases but migration to nearer destinations declines.
For the vapor mill it means that over time between any two locations you should first see migration increase then decrease. And the switching point from increase to decrease should come later for locations farther apart.
By the way if you would like to see more pictures of delicious food in Singapore you can follow my photo stream. But beware it might make you want to migrate.


Take three siblings equally spaced in age. Here’s an advantage the second child has over the third.
When the oldest learns something new, the second will have a chance to learn a little of it alongside. For example, say the parents are teaching the oldest algebra in the car while on vacation (dreadful parents for sure.) All three siblings will be listening but the second, being older than the youngest is going to grasp more of it.
Now when the second reaches the same age that the oldest was at the time of the algebra lesson, the second will be more advanced than the oldest was as a result of the spillovers from the original lesson. The parents will know this and they will appropriately scale up the lesson. It will go faster and it will be more advanced. As a result the lesson will be less accessible to the youngest child than the original lesson to the oldest was to the second. The third child will benefit less from the spillovers than the second child did.
This process implies that the human capital of the second will closely track the oldest and diverge from the youngest so that parental investments tailored to the current human capital level of the oldest will have benefit the second more than the youngest by an ever increasing differential. And investments tailored to the level of the second will be too advanced to benefit the youngest.
Now the original assumption was that the siblings are equally spaced in age. Suppose instead that the two youngest are close in age and the oldest is much older. Then there will be little scope for spillovers from the oldest to the second. The second will have to be taught everything from scratch and now the youngest is going to receive the only spillovers. So the larger gap in age between the oldest and the second the smaller the advantage of the second over the third. And for a large enough gap the advantage reverses.
Treatment 1 is you give people a cookie and some cake and you ask them to rate how much they like the cookie better (which of course would be negative if they like the cake better.)
Treatment 2 is you present them with the cookie and the cake and you let them choose. Then you also give them the other item and have them rate just as in treatment 1.
Of course those in treatment 2 are going to rate their chosen item higher on average than those in treatment 1. But let’s look at the overall variance in ratings. A behavioral hypothesis is that the variance is larger in treatment 2 due to cognitive dissonance. Those who expressed a preference will want to rationalize their preference an this will lead them to exaggerate their rating.
Now I wouldn’t be surprised if an experiment like that has already been done and found evidence of cognitive dissonance. The next twist will explore the effect in more detail.
The cookies will be tinged with a random quantity of some foul tasting ingredient, unknown to the subjects. Let’s think of the quantity as ranging from 0 to 100. We want to plot the quantity on the x-axis versus the rating on the y.
My hopothesis is about how this relation differs between the two treatments. At an individual level here is what I would expect to see. Consider a subject who likes cookies better. In treatment 1 he will have a continuous and decreasing curve which will cross zero at some quantity. I.e too much of the yucky stuff and he rates the cake higher.
In treatment 2 his curve will be shifted upward but only in the region where his treatment 2 rating is positive. At higher quantities the curve exactly coincides with the treatment 1 curve.
I have in mind the following theory. There is a psychic cost of convincing yourself that you like something that tastes bad. Cognitive dissonance leads you to do that. But when the cookie tastes so bad that it’s beyon your capacity to convince yourself otherwise you save yourself the psychic cost and don’t even try.
Now we won’t have such data at an individual level to see this. The challenge is to identify restrictions on the aggregate data that the hypothesis implies.

Here’s a model of self-confidence. People meet you and they decide if they admire/respect/lust after you. You can tell if they do. When they do you learn that you are more admirable/respectable/attractive than you previously knew you were. Knowing this increases your expectation that the next person will react the same way. That means that when you meet the next person you are less nervous about how they will judge you. This is self-confidence.
Your self-confidence makes a visible impression on that next person. And it’s no accident that your self-confidence makes them admire/respect/lust after you more than they would if you were less self-confident. Because your self-confidence reveals that the last person felt the same way. When trying to figure out whether you are someone worthy of admiration respect or lust, it is valuable information to know how other people decided because people have similar tastes on those dimensions.
And of course it works in the opposite direction too. People who are judged negatively lose self-confidence and their unease is visible to others and makes a poor impression.
For this system to work well it must escape herding and prevent manipulation. Herding would be a problem if confident people ignore that others admire them only because they are confident and they allow these episodes to further fuel their confidence. I believe that the self-confidence mechanism is more sophisticated than this. Celebrities complain about being unable to have real relationships with regular people because regular people are unable to treat celebrities like regular people. A corollary of this is that a celebrity does not gain any more confidence from being mobbed by fans. A top-seeded tennis player doesn’t gain any further boost in confidence from a win over a low-ranked opponent who wilts on the court out of awe and intimidation.
Herding may be harder to avoid on the downside. If people who lack confidence are shunned they may never get the opportunity to prove themselves and escape the confidence trap.
And notwithstanding self-help books that teach you tricks to artificially boost your self-confidence, I don’t think manipulation is a problem either. Confidence is an entry, nothing more. When you are confident people are more willing to get to know you better. But once they do they will learn whether your self-confidence is justified. If it isn’t you may be worse off than if you never had the entry in the first place.
Drawing: Life is a Zen Roller Coaster from http://www.f1me.net
How much do your eyes betray you?
Have two subjects play matching pennies. They will face each other but separated by a one-way mirror. Only one subject will be able to see the other’s face. He can only see the face, not anything below the chin.
Each subject selects his action by touching a screen. Touch the screen to the West to play Heads, touch the screen on the East to play Tails. (East-West rather than left-right so that my Tails screen is on the same side as your Tails screen. This makes it easier to keep track.)
You have to touch a lighted region of the screen in order to have your move registered and the lighted region is moving around the screen. This is going to require you to look at the screen you want to touch. But you can look in one direction and then the other and touch only the screen you want. Your hands are not visible to the other subject.
How much more money is earned by the player who can see the other’s eyes?
(Conversation with Adriana Lleras-Muney)
My brother-in-law wanted to sell something with an auction but first he wanted to assemble as many interested buyers as he could. His problem is that while he knew there were many interested buyers in the world he didn’t know who they were or how to find them. But he had a good idea: people who are interested in his product probably know other people who are also interested. He asked me for advice on how to use finders’ fees to incentivize the buyers he already know about to introduce him to any new potential buyers they know.
This is a very interesting problem because it interacts two different incentive issues. First, to get someone to refer you to someone they know you have to confront a traditional bilateral monopoly problem. You are a monopoly seller of your product but your referrer is a monopoly provider of access to his friend because only he knows which and how many of his friends are interested. If your finder’s fee is going to work it’s going to have to give him his monopoly rents.
The interesting twist is that your referrer has an especially strong incentive not to give you any references. Because anybody he introduces to you is just going to wind up being competition for him in the auction for your product. So your finder’s fee has to be even more generous in order to compensate your referrer for the inevitable reduction in the consumer’s surplus he was expecting from the auction.
I told my brother-in-law not to use finder’s fees. That can’t be the optimal way to solve his problem. Because there is another instrument he has at his disposal which must be the more efficient way to deal with this compound incentive problem.
Here’s the problem with finder’s fees. Every dollar of encouragement I give to my buyers is going to cost me a full dollar. But I have a way to give him a dollar’s worth of encouragement at a cost to me of strictly less than a dollar. I leverage my monopoly power and I use the object I am selling as the carrot.
In fact there is a basic principle here which explains not only why finder’s fees are bad incentive devices but also why employers give compensation in the form of employee discounts, why airlines use frequent flier miles as kickbacks and why a retailer would always prefer to give you store credit rather than cash refunds. It costs them less than a dollar to provide you with a dollar’s value.
Why is that? Because any agent with market power inefficiently under-provides his product. By setting high prices, he creates a wedge between his cost of supplying the good and your value for receiving it. If he wants to do you a favor he could either give you cash or he could give you the cash value in product. It’s always cheaper to do the latter.
So what does this say about incentivizing referrals to an auction? How do you “use the object” in place of a finder’s fee? The optimal way to do that is the following. You tell your potential referrer that you will give him an advantage in the auction if he brings to you a new potential buyer. Because you are a monopoly auctioneer there is always a wedge that you can capitalize on to do this at minimal cost to yourself.
In this particular example the wedge is your reserve price. Your referrer knows that you are going to extract your profits by setting a high reserve price and thereby committing not to sell the object if he is not willing to pay at least that much. You will induce your referrer to bring in new competition by offering to lower his reserve price when he does.
Now of course you have to deal with the problem of collusion and shills. Of course that’s a problem in any auction and even more of a problem with monetary finder’s fees but that’s a whole nuther post.
(Ongoing collaboration with Ahmad Peivandi)
Subjects video chat with each other. In one treatment subject A sees her own image in a small window in the corner of the chat, and in the other treatment (the control) there is no small window and she sees only the chat partner.
Subject B is not told about the two treatments and is simply asked to report how attractive subject A is. We want to know whether attractiveness is higher in the self-image treatment versus the control treatment.
This gets at a few different issues but the one I am curious about is this: do people know what it is about them that makes them attractive to others?
Also, we would want to track eye movements during the chat.
Suppose you and I are playing a series of squash matches and we are playing best 2 out of 3. If I win the first match I have an advantage for two reasons. First is the obvious direct reason that I am only one match short of wrapping up the series while you need to win the next two. Second is the more subtle strategic reason, the discouragement effect. If I fight hard to win the next match my reward is that my job is done for the day, I can rest and of course bask in the glow of victory. As for you, your effort to win the second match is rewarded by even more hard work to do in the third match.
Because you are behind, you have less incentive than me to win the second match and so you are not going to fight as hard to win it. This is the discouragement effect. Many people are skeptical that it has any measurable effect on real competition. Well I found a new paper that demonstrates an interesting new empirical implication that could be used to test it.
Go back to our squash match and now lets suppose instead that it’s a team competition. We have three players on our teams and we will match them up according to strength and play a best two out of three team competition. Same competition as before but now each subsequent game is played by a different pair of players.
A new paper by Fu, Lu, and Pan called “Team Contests With Multiple Pairwise Battles” analyzes this kind of competition and shows that they exhibit no discouragement effect. The intuition is straightforward: if I win the second match, the additional effort that would have to be spent to win the third match will be spent not by me, but by my teammate. I internalize the benefits of winning because it increases the chance that my team wins the overall series but I do not internalize the costs of my teammate’s effort in the third match. This negative externality is actually good for team incentives.
The implied empirical prediction is the following. Comparing individual matches versus team matches, the probability of a comeback victory conditional on losing the first match will be larger in the team competition. A second prediction is about the very first match. Without the discouragement effect, the benefit from winning the first match is smaller. So there will be less effort in the first match in the team versus individual competition.
My son and I went to see the Cubs last week as we do every Spring.
The Cubs won 8-0 and Matt Garza was one out away from throwing a complete game shutout, a rarity for a Cub. The crowd was on its feet with full count to the would-be final batter who rolled the ball back to the mound for Garza to scoop up and throw him out. We were all ready to give a big congratulatory cheer and then this happened. This is a guy who was throwing flawless pitches to the plate for nine innings and here with all the pressure gone and an easy lob to first he made what could be the worst throw in the history of baseball and then headed for the showers. Cubs win!
But this Spring we weren’t so interested in the baseball out on the field as we were in the strategery down in the toilet. Remember a while back when I wrote about the urinal game? It seems like it was just last week (fuzzy vertical lines pixellating then unpixellating the screen to reveal the flashback:)
Consider a wall lined with 5 urinals. The subgame perfect equilibrium has the first gentleman take urinal 2 and the second caballero take urinal 5. These strategies are pre-emptive moves that induce subsequent monsieurs to opt for a stall instead out of privacy concerns. Thus urinals 1, 3, and 4 go unused.
So naturally we turn our attention to The Trough.

A continuous action space. Will the trough induce a more efficient outcome in equilibrium than the fixed array of separate urinals? This is what you come Cheap Talk to find out.
Let’s maintain the same basic parameters. Assume that the distance between the center of two adjacent urinals is d and let’s consider a trough of length 5d, i.e. the same length as a 5 side-by-side urinals (now with invincible pink mystery ice located invitingly at positions d/2 + kd for k = 1, 2, 3, 4.) The assumption in the original problem was that a gentleman pees if and only if there is nobody in a urinal adjacent to him. We need to parametrize that assumption for the continuos trough. It means that there is a constant r such that he refuses to pee in a spot in which someone is currently peeing less than a distance r from him. The assumption from before implies that d < r < 2d. Moreover the greater the distance to the nearest reliever the better.
The first thing to notice is that the equilibrium spacing from the original urinal game is no longer a subgame-perfect equilibrium. In our continuous trough model that spacing corresponds to gentlemen 1 and 2 locating themselves at positions d/2 and 7d/2 measured from the left boundary of the trough. Suppose r <= 3d/2. Then the third man can now utilize the convex action space and locate himself at position 2d where he will be a comfortable distance 3d/2>= r away from the other two. If instead r > 3d/2, then the third man is strictly deterred from intervening but this means that gentleman number 2 would increase his personal space by locating slightly farther to the right whilst still maintaining that deterrence.
So what does happen in equilibrium? I’ve got good news and bad news. The good news first. Suppose that r < 5d/4. Then in equilibrium 3 guys use the trough whereas only 2 of the arrayed urinals were used in the original equilibrium. In equilibrium the first guy parks at d/2 (to be consistent with the original setup we assume that he cannot squeeze himself any closer than that to the left edge of the trough without risking a splash on the shoes) the second guy at 9d/2 and the third guy right in the middle at 5d/2. They are a distance of 2d> r from one another, and there is no room for anybody else because anybody who came next would have to be standing at most a distance d< r from two of the incumbents. This is a subgame perfect equilibrium because the second guy knows that the third guy will pick the midpoint and so to keep a maximal distance he should move to the right edge. And foreseeing all of this the first guy moves to the left edge.
Note well that this is not a Pareto improvement. The increased usage is offset by reduced privacy.They are only 2d away from each other whereas the two urinal users were 3d away from each other.
Now the bad news when r >5d/4. In this case it is possible for the first two to keep the third out. For example suppose that 1 is at 5d/4 and 2 is at 15d/4. Then there is no place the third guy can stand and be more than 5d/4 away hence more than r from the others. In this case the equilibrium has the first two guys positioning themselves with a distance between them equal to exactly 2r, thus maximizing their privacy subject to the constraint that the third guy is deterred. (One such equilibrium is for the first two to be an equal distance from their respective edges, but there are other equilibria.)
The really bad news is that when r is not too large, the two guys even have less privacy than with the urinals. For example if r is just above 5d/4 then they are only 10d/4 away from each other which is less than the 3d distance from before. What’s happening is that the continuous trough gives more flexibility for the third guy to squeeze between so the first two must stand closer to one another to keep him away.
Instant honors thesis for any NU undergrad who can generalize the analysis to a trough of arbitrary length.
Bicycle “sprints.” This is worth 6 minutes of your time.
Thanks to Josh Knox for the link.


In basketball the team benches are near the baskets on opposite sides of the half court line. The coaches roam their respective halves of the court shouting directions to their team.
As in other sports the teams switch sides at halftime but the benches stay where they were. That means that for half of the game the coaches are directing their defenses and for the other half they are directing their offenses.
If coaching helps then we should see more scoring in the half where the offenses are receiving direction.
This could easily be tested.
Over the course of your life you have to decide your position on a number of philosophical/social/political issues. You are open-minded so you collect as much data as you can before forming an opinion. But you are human and you can only remember so many facts.
There will come a time when the data you have collected make a very strong case for one particular position on issue A, say the right-wing position. When that happens you are pretty sure that there is never going to be enough evidence to overturn your position.
That’s not because you are closed-minded. That’s because you are very open-minded and based on the weight of all the evidence you collected and processed as objectively as a person can do, you have concluded that its very likely that this is the right position on A. And the fact that this is very likely the right position on A does not just imply but is indeed equivalent to saying that you attach very low probability to the future occurrence of strong evidence in the other direction.
Now that means that there’s not much point in collecting any more information about A. And indeed there’s not much point in remembering the detailed information that led you to this conclusion. The only reason for doing that would be to weigh it against future evidence but we’ve already established that this is unlikely to make any difference.
So what you optimally, rationally, perfectly objectively do is allow yourself to forget everything you know about A including all the reasons that justify your strongly-held views on A and to just make an indelible mental note that “The right-wing position on A is the correct one no matter what anyone else says and no matter what evidence to the contrary should come along in the future.”
The reason this is the rational thing to do is that you have scarce memory space. By allowing those memories to fade away you free up storage space for information about issues B, C, and D which you are still carefully collecting information on, forming an objective opinion about, in preparation for eventually also adopting a well-informed dogmatic opinion about.
- If you have a blog and you write about potential research questions, write the question out clearly but give a wrong answer. This solves the problem I raised here.
- When I send an email to two people I feel bad for the person whose name I address second (“Dear Joe and Jane”) so I put it twice to make it up to them (“Dear Joe and Jane and Jane.”)
- If you have a rich country and a poor country and their economies are growing at the same rate you will nevertheless have rising inequality over time simply because, as is well documented, the poor have more kids.
- Are there arguments against covering contraception under health insurance that don’t also apply to covering vaccines?
- The most interesting news is either so juicy that the source wants it kept private or so important that the source wants to make it public. This is why Facebook is an inferior form of communication: as neither private nor fully public it is an interior minimum.
Email is the superior form of communication as I have argued a few times before, but it can sure aggravate your self-control problems. I am here to help you with that.
As you sit in your office working, reading, etc., the random email arrival process is ticking along inside your computer. As time passes it becomes more and more likely that there is email waiting for you and if you can’t resist the temptation you are going to waste a lot of time checking to see what’s in your inbox. And it’s not just the time spent checking because once you set down your book and start checking you won’t be able to stop yourself from browsing the web a little, checking twitter, auto-googling, maybe even sending out an email which will eventually be replied to thereby sealing your fate for the next round of checking.
One thing you can do is activate your audible email notification so that whenever an email arrives you will be immediately alerted. Now I hear you saying “the problem is my constantly checking email, how in the world am i going to solve that by setting up a system that tells me when email arrives? Without the notification system at least I have some chance of resisting the temptation because I never know for sure that an email is waiting.”
Yes, but it cuts two ways. When the notification system is activated you are immediately informed when an email arrives and you are correct that such information is going to overwhelm your resistance and you will wind up checking. But, what you get in return is knowing for certain when there is no email waiting for you.
It’s a very interesting tradeoff and one we can precisely characterize with a little mathematics. But before we go into it, I want you to ask yourself a question and note the answer before reading on. On a typical day if you are deciding whether to check your inbox, suppose that the probability is p that you have new mail. What p is going to get you to get up and check? We know that you’re going to check if p=1 (indeed that’s what your mailbeep does, it puts you at p=1.) And we know that you are not going to check when p=0. What I want to know is what is the threshold above which its sufficiently likely that you will check and below which is sufficiently unlikely so you’ll keep on reading? Important: I am not asking you what policy you would ideally stick to if you could control your temptation, I am asking you to be honest about your willpower.
Ok, now that you’ve got your answer let’s figure out whether you should use your mailbeep or not. The first thing to note is that the mail arrival process is a Poisson process: the probability that an email arrives in a given time interval is a function only of the length of time, and it is determined by the arrival rate parameter r. If you receive a lot of email you have a large r, if the average time spent between arrivals is longer you have a small r. In a Poisson process, the elapsed time before the next email arrives is a random variable and it is governed by the exponential distribution.
Let’s think about what will happen if you turn on your mail notifier. Then whenever there is silence you know for sure there is no email, p=0 and you can comfortably go on working temptation free. This state of affairs is going to continue until the first beep at which point you know for sure you have mail (p=1) and you will check it. This is a random amount of time, but one way to measure how much time you waste with the notifier on is to ask how much time on average will you be able to remain working before the next time you check. And the answer to that is the expected duration of the exponential waiting time of the Poisson process. It has a simple expression:
Expected time between checks with notifier on =
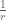
Now let’s analyze your behavior when the notifier is turned off. Things are very different now. You are never going to know for sure whether you have mail but as more and more time passes you are going to become increasingly confident that some mail is waiting, and therefore increasingly tempted to check. So, instead of p lingering at 0 for a spell before jumping up to 1 now it’s going to begin at 0 starting from the very last moment you previously checked but then steadily and continuously rise over time converging to, but never actually equaling 1. The exponential distribution gives the following formula for the probability at time T that a new email has arrived.
Probability that email arrives at or before a given time T =
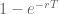
Now I asked you what is the p* above which you cannot resist the temptation to check email. When you have your notifier turned off and you are sitting there reading, p will be gradually rising up to the point where it exceeds p* and right at that instant you will check. Unlike with the notification system this is a deterministic length of time, and we can use the above formula to solve for the deterministic time T at which you succumb to temptation. It’s given by
Time between checks when the notifier is off =

And when we compare the two waiting times we see that, perhaps surprisingly, the comparison does not depend on your arrival rate r (it appears in the numerator of both expressions so it will cancel out when we compare them.) That’s why I didn’t ask you that, it won’t affect my prescription (although if you receive as much email as I do, you have to factor in that the mail beep turns into a Geiger counter and that may or may not be desirable for other reasons.) All that matters is your p* and by equating the two waiting times we can solve for the crucial cutoff value that determines whether you should use the beeper or not.
The beep increases your productivity iff your p* is smaller than
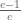
This is about .63 so if your p* is less than .63 meaning that your temptation is so strong that you cannot resist checking any time you think that there is at least a 63% chance there is new mail waiting for you then you should turn on your new mail alert. If you are less prone to temptation then yes you should silence it. This is life-changing advice and you are welcome.
Now, for the vapor mill and feeling free to profit, we do not content ourselves with these two extreme mechanisms. We can theorize what the optimal notification system would be. It’s very counterintuitive to think that you could somehow “trick” yourself into waiting longer for email but in fact even though you are the perfectly-rational-despite-being-highly-prone-to-temptation person that you are, you can. I give one simple mechanism, and some open questions below the fold.
Here’s a card game: You lay out the A,2,3 of Spades, Diamonds, Clubs in random order on the table face up. So that’s 9 cards in total. There are two players and they take turns picking up cards from the table, one at a time. The winner is the first to collect a triplet where a triplet is any one of the following sets of three:
- Three cards of the same suit
- Three cards of the same value
- Ace of Spaces, 2 of Diamonds, 3 of Clubs
- Ace of Clubs, 2 of Diamonds, 3 of Spades
Got it? Ok, this game can be solved and the solution is that with best play the result is a draw, neither player can collect a triplet. See if you can figure out why. (Drew Fudenberg got it almost immediately [spoiler.]) Answer and more discussion are after the jump.
Models of costly voting give rise to strategic turnout: in a district in which party A has a big advantage, supporters of party A will have low turnout in equilibrium in order to make the election close. That’s because only when the election is close will voters have an incentive to turnout and vote, which is costly.
Looking at elections data it is hard to identify strategic turnout. Low turnout is perfectly consistent with non-strategic voters who just have high costs of voting.
Redistricting offers an interesting source of variation that could help. Suppose that a state has just undergone redistricting and a town has been moved from a district with a large majority for one party into a more competitive district. Non-strategic voters in that town will not change their behavior.
But strategic voters will have different incentives in the new district. In particular we should see an increase in turnout among voters in the town that is new to the district. And this increase in turnout should be larger than any change in turnout observed for voters who remained in the district before and after redistricting.
There are probably a slew of testable implications that could be derived from models of strategic turnout based on whether the new district is more or less competitive than the old one, whether the stronger party is the same or different from the stronger party in the old district, and whether the town leans toward or against the stronger party in the new district.
In many situations, such reinforcement learning is an essential strategy, allowing people to optimize behavior to fit a constantly changing situation. However, the Israeli scientists discovered that it was a terrible approach in basketball, as learning and performance are “anticorrelated.” In other words, players who have just made a three-point shot are much more likely to take another one, but much less likely to make it:
What is the effect of the change in behaviour on players’ performance? Intuitively, increasing the frequency of attempting a 3pt after made 3pts and decreasing it after missed 3pts makes sense if a made/missed 3pts predicted a higher/lower 3pt percentage on the next 3pt attempt. Surprizingly [sic], our data show that the opposite is true. The 3pt percentage immediately after a made 3pt was 6% lower than after a missed 3pt. Moreover, the difference between 3pt percentages following a streak of made 3pts and a streak of missed 3pts increased with the length of the streak. These results indicate that the outcomes of consecutive 3pts are anticorrelated.
This anticorrelation works in both directions. as players who missed a previous three-pointer were more likely to score on their next attempt. A brick was a blessing in disguise.
The underlying study, showing a “failure of reinforcement learning” is here.
Suppose you just hit a 3-pointer and now you are holding the ball on the next possession. You are an experienced player (they used NBA data), so you know if you are truly on a hot streak or if that last make was just a fluke. The defense doesn’t. What the defense does know is that you just made that last 3-pointer and therefore you are more likely to be on a hot streak and hence more likely than average to make the next 3-pointer if you take it. Likewise, if you had just missed the last one, you are less likely to be on a hot streak, but again only you would know for sure. Even when you are feeling it you might still miss a few.
That means that the defense guards against the three-pointer more when you just made one than when you didn’t. Now, back to you. You are only going to shoot the three pointer again if you are really feeling it. That’s correlated with the success of your last shot, but not perfectly. Thus, the data will show the autocorrelation in your 3-point shooting.
Furthermore, when the defense is defending the three-pointer you are less likely to make it, other things equal. Since the defense is correlated with your last shot, your likelihood of making the 3-pointer is also correlated with your last shot. But inversely this time: if you made the last shot the defense is more aggressive so conditional on truly being on a hot streak and therefore taking the next shot, you are less likely to make it.
(Let me make the comparison perfectly clear: you take the next shot if you know you are hot, but the defense defends it only if you made the last shot. So conditional on taking the next shot you are more likely to make it when the defense is not guarding against it, i.e. when you missed the last one.)
You shoot more often and miss more often conditional on a previous make. Your private information about your make probability coupled with the strategic behavior of the defense removes the paradox. It’s not possible to “arbitrage” away this wedge because whether or not you are “feeling it” is exogenous.
Faced with a morally ambiguous choice, you are sometimes torn between conflicting motivations. And it can get to the point where you can’t really figure out which one is really driving you. Are you calling your old girlfriend because only she can give you the right advice about your sick cat, or because you just want to hear her voice? Are you recommending your colleague for the committee because he’s the right guy for the job or because you don’t want to do it yourself? Do you write a daily blog because it’s a great way to hash out new ideas or because you just love the attention?
From a conventional point of view its hard to understand how we could doubt our own motivations. At the moment of decision we can articulate at a conscious level what the right objective is. (If not, then on what basis would we have to be suspicious of ourselves?) And we should evaluate all the possible consequences of the action that tempts us in light of that objective and make the best choice.
So self-doubt is a smoking gun showing that this conventional framework omits an important friction. Here’s my theory what that friction is.
Information comes in millions of tiny pieces over time. It is beyond our memory and our conscious capacity to recall and assemble all of those data when called upon to make a decision that relies on it. Instead we discard the details and just store summary statistics. When it comes time to make a decision, the memory division of our decision-making apparatus steps up and presents the relevant summary statistics.
The instinctive feeling that “I should do X” is what it feels like when the reported summary statistics point in favor of X. It has an instinctive quality because it is entirely pre-conscious. Conscious deliberation begins only after that initial inclination is formed.
At that stage your task is to verify whether the proposed course of action is consistent with your current motivation and the specific details of the situation you find yourself in. But that decision is necessarily made with limited information because you only have the summary statistics to go on.
Any divergence between your present frame of mind and the frame of mind that you were in when you recorded and stored those summary statistics can give you cause for doubting your instincts.
That suggests an interesting behavioral framework. The decision maker is composed of two agents, an Advisor and a Decider. The Advisor has all of the information about the payoffs to different actions and he makes recommendations to the Decider who then takes an action. The friction is that the Advisor and Decider’s preferences are different and the difference fluctuates over time. Thus, at any point in time the Decider must resolve a conflict between his own objective and the unknown objective of the Advisor.
I write all the time about strategic behavior in athletic competitions. A racer who is behind can be expected to ease off and conserve on effort since effort is less likely to pay off at the margin. Hence so will the racer who is ahead, etc. There is evidence that professional golfers exhibit such strategic behavior, this is the Tiger Woods effect.
We may wonder whether other animals are as strategically sophisticated as we are. There have been experiments in which monkeys play simple games of strategy against one another, but since we are not even sure humans can figure those out, that doesn’t seem to be the best place to start looking.
I would like to compare how humans and other animals behave in a pure physical contest like a race. Suppose the animals are conditioned to believe that they will get a reward if and only if they win a race. Will they run at maximum speed throughout regardless of their position along the way? Of course “maximum speed” is hard to define, but a simple test is whether the animal’s speed at a given point in the race is independent of whether they are ahead or behind and by how much.
And if the animals learn that one of them is especially fast, do they ease off when racing against her? Do the animals exhibit a tiger Woods effect?
There are of course horse-racing data. That’s not ideal because the jockey is human. Still there’s something we can learn from horse racing. The jockey does not internalize 100% of the cost of the horse’s effort. Thus there should be less strategic behavior in horse racing than in races between humans or between jockey-less animals. Dog racing? Does that actually exist?
And what if a dog races against a human, what happens then?

Doctors sometimes resist prescribing costly diagnostic procedures, saying that the result of the test would be unlikely to affect the course of treatment. But what we know about placebo effects for medicine should have implications also for the value of information, even when it leads to no objective health benefits.
I have a theory of how placebos work. The idea is that our bodies, either through conscious choices that we make or simply through physiological changes, must make an investment in order to get healthy. Being sick is like being, perhaps temporarily, below the threshold where the body senses that the necessary investment is worth it. A placebo tricks the body into thinking that we are going to get at least marginally more healthy and that pushes above the threshold triggering the investment which makes us healthy.
The same idea can justify providing information that has no instrumental value. Suppose you have an injury and are considering having an MRI to determine how serious it is. Your doctor says that surgery is rarely worthwhile and so even if the MRI shows a serious injury it won’t affect how you are treated.
But you want to know. For one thing the information can affect how you personally manage the injury. That’s instrumental value that your doctor doesn’t take into account.
But even if there were nothing you could consciously do based on the test result, there may be a valuable placebo reason to have the MRI. If you find out that the injury is mild, the psychological effect of knowing that you are healthy (or at least healthier than you previously thought) can be self-reinforcing.
The downside of course is that when you find out that the injury is serious you get an anti-placebo effect. So the question is whether you are better off on average when you become better informed about your true health status.
If the placebo effect works because the belief triggers a biological response then this is formally equivalent to a standard model of decision-making under uncertainty. Whenever a decision-maker will optimally condition his decision on the realization of information, then the expected value of learning that information is positive.
In the past few weeks Romney has dropped from 70% to under 50% and Gingrich has rocketed to 40% on the prediction markets. And in this time Obama for President has barely budged from its 50% perch. As someone pointed out on Twitter (I forget who, sorry) this is hard to understand.
For example if you think that in this time there has been no change in the conditional probabilities that either Gingrich or Romney beats Obama in the general election, then these numbers imply that the market thinks that those conditional probabilities are the same. Conversely, If you think that Gingrich has risen because his perceived odds of beating Obama have risen over the same period, then it must be that Romney’s have dropped in precisely the proportion to keep the total probability of a GOP president constant.
It’s hard to think of any public information that could have these perfectly offsetting effects. Here’s the only theory I could come up with that is consistent with the data. No matter who the Republican candidate is, he has a 50% chance of beating Obama. This is just a Downsian prediction. The GOP machine will move whoever it is to a median point in the policy space. But, and here’s the model, this doesn’t imply that the GOP is indifferent between Gingrich and Romney.
While any candidate, no matter what his baggage, can be repositioned to the Downsian sweet spot, the cost of that repositioning depends on the candidate, the opposition, and the political climate. The swing from Romney to Gingrich reflects new information about these that alters the relative cost of marketing the two candidates. Gingrich has for some reason gotten relatively cheaper.
I didn’t say it was a good theory.
Update: Rajiv Sethi reminded me that the tweet was from Richard Thaler. (And see Rajiv’s comment below.)

You and your partner have to decide on a new venture. Maybe you and your sweetie are deciding on a movie, you and your co-author are deciding on which new idea to develop, or you and your colleague are deciding which new Assistant Professor to hire.
Deliberation consists of proposals and reactions. When you pitch your idea you naturally become attached to it. Its your idea, your creation. Your feelings are going to be hurt if your partner doesn’t like it.
Maybe you really are a dispassionate common interest maximizer, but there’s no way for your partner to know that for sure. You try to say “give me your honest opinion, I promise I have thick skin, you won’t hurt my feelings.” But you would say that even if it’s a little white lie.
The important thing is that no matter how sensitive you actually are, your partner believes that there is a chance your feelings will be hurt if she shoots down your idea. And she might even worry that you would respond by feeling resentful towards her. All of this makes her reluctant to give her honest opinion about your idea. The net result is that some inferior projects might get adopted because concern for hurt feelings gets in the way of honest information exchange.
Unless you design the mechanism to work around that friction. The basic problem is that when you pitch your idea it becomes common knowledge that you are attached to it. From that moment forward it is common knowledge that any opinion expressed about the idea has the chance of causing hurt feelings.
So a better mechanism would change the timing to remove that feature. You and your partner first announce to one another which options are unacceptable to you. Now all of the rejections have been made before knowing which ones you are attached to. Only then do you choose your proposal from the acceptable set.
If your favorite idea has been rejected then for sure you are disappointed. But your feelings are not hurt because it is common knowledge that her rejection is completely independent of your attachment. And for exactly that reason she is perfectly comfortable being honest about which options are unacceptable.
This is going to work better for movies, and new Assistant Professors than it is for research ideas. Because we know in advance the universe of all movies and job market candidates.
Research ideas and other creative ventures are different because there is no way to enumerate all of the possibilities beforehand and reject the unacceptable ones. Indeed the real value of a collaborative relationship is that the partners are bringing to the table brand new previously unconceived-of ideas. This makes for a far more delicate relationship.
We can thus classify relationships according to whether they are movie-like or idea-like, and we would expect that the first category are easier to sustain with second-best mechanisms whereas the second require real trust and honesty.
(inspired by a conversation with +Emil Temnyalov and Jorge Lemus)
