
You are currently browsing the tag archive for the ‘the web’ tag.

If you are like me you subscribe to many RSS feeds and you find them accumulating articles faster than you can read them. What do you do when MetaFilter has 500 unread articles?
Use the glance and scroll method. Look at an article and read it if it looks interesting. But if it doesnt then don’t keep browsing. Give a hard flick on your mousewheel, trackpad, phone screen whatever and scroll rapidly past a large number of articles and glance at the next one you land on. Repeat.
The point is that all articles, regardless of their position in the feed are equally likely to be interesting, other things equal. So if you can only read a fraction of what’s there you can’t do any worse than this. But in fact other things are not equal.
The quality of articles is endogenously serially correlated. Because any blog runs the best material available that day/couple of days/week. If you landed on a lame article then chances are you landed on a lame day. Scroll your way out of that trough and hope you land on a peak.
Steve Tadelis, Distinguished Economist at eBay and his colleagues have done an experiment and seem to have concluded that its a waste of money to pay for sponsored links on Google when Google’s regular search algorithm shows links to eBay for free.
Before you read the rest of this post, go to Google and try searching for “Amazon.” You’ll probably notice that the top two listings are both for Amazon’s website, with the first appearing on a light beige background. If you click on the first — a paid search ad — Amazon will pay Google for attracting your business. If you click on the second, Amazon gets your business but Google gets nothing. Try “Macys,” “Walgreens,” and “Sports Authority” — you’ll see the same thing.
If you search for eBay, though, you’ll find only a single listing — an unpaid one. Odds are, after marketers at Amazon, Walgreens and elsewhere catch wind of a preliminary study released on Friday, their search listings will start to look a lot more like eBay’s. The study — by eBay Research Labs economists Thomas Blake, Chris Nosko, and Steve Tadelis — analyzed eBay sales after shutting down purchases of search ads on Google and elsewhere, while maintaining a control set of regions where search ads continued unchanged. Their findings suggest that many paid ads generate virtually no increase in sales, and even for ones that do, the sales benefits are far eclipsed by the cost of the ads themselves.
This is a dilemma for Google. Because it suggests that the way to capitalize on the popularity of their search algorithm is to discriminate against those who don’t pay for ads. But unless Google reinvents itself as a full-blown paid advertising site, such discrimination is likely to raise legal issues.
Here I am on the podcast Hang Up And Listen with hosts Stefan Fatsis, Mike Pesca and Josh Levin. Its a sports oriented podcast and I am talking about Purple Pricing. They had some very good questions. I come in at about the 25 minute mark.
We have coordinated on April 1 as the date where everyone gets to indulge their latent desire to say something false and hope that it gets believed. The problem of course is that as a result nothing you say on April 1 is believed. Credibility has a public good aspect to it and the social optimum would conserve enough of it so that at least some of us could feed our hilarious public deception jones.
(You might argue otherwise. By reducing credibility across the board we set the stage for the truly exceptional liars to show their stuff fooling people even though everyone was expecting them to do exactly that.)
It soon becomes tempting to start making up stuff on the day before April 1, and then eventually sooner. Whether, how, and why this unfolds depends on just what are the basic forces at work here, a question about which we can only theorize. We know by revealed preference that people want to say made-up stuff. But its more than that, you want people to believe it, pass it on and then get called out for believing a fake story. And the best kind of April Fools story is the kind that is ex post so obviously fake that the foolee looks especially gullible.
All of these suggest that April 1 is the least ideal day for April Fools. So then we can ask why are April Fools pranks perpetrated on April 1 and not some other day? Is it because April 1 gives you reputational cover for reporting bogus stories? It sounds like a good theory, and if it were true we would not have to worry about March 31 Fools and the eventual Year-Round Fools. But it doesn’t seem to survive closer scrutiny. If my reputation for legitimate reporting is safe for that one day it must be because nobody expects me to do legitimate reporting that day. But then April 1 is the last day I would want to be dropping my April Fools.
Instead I think its something more subtle. The perfect April Fools prank works by first roping in the reader but then slowly revealing clues that remind her that its April Fools and you have been had. April 1 plays a crucial role in this development. The Reveal would not come with the same impact on any July 19. Indeed the best April Fools pranks tell you the date somewhere along the way. Its how you say to the reader “look at you, you forgot about April Fools, and I got you” without actually saying that. And it provides ammunition when he blindly passes the story on and his friends can say “check the date.”
So April Foolers need the following epistemic infrastructure for their pranks: 1) The possibility of surprise, 2) The expectation of surprise. And clearly it cannot be an equilibrium to have both of these if the source of #2 is to be contained in a single date April 1. Once there is too much of #2, there’s precious too little of #1.
And that’s when the pre-emption begins. By publishing your April Fool on March 31, you get more of 1), and still pretty much the same amount of 2). Until of course everybody starts doing that and the unraveling continues. (We are already getting close.)
There is one bright side to all of this. When everybody has come to expect that whatever you say on April 1 is false, you may indeed no longer be able to fool people into believing something you made up. But the flipside is a welcome opportunity for many wishing to come clean at minimum cost. You now have a day when you can tell the truth and have nobody believe you.
There’s someone you want to hook up with. How do you find out if the attraction is mutual while avoiding the risk of rejection? That is simply not possible no matter how sophisticated a mechanism you use. Because in order for the mechanism to determine whether the attraction is mutual you must communicate your desire to hook up but she’s not that into you, well you are going to be rejected.
But rejection per se is not the real risk. Because if she rejects you without ever actually knowing it, you will be disappointed but you won’t be embarrassed. The real cost of rejection comes only when rejection is common knowledge between the rejector and the rejected.
So to design a mechanism that maximizes the number of hookups you need to give people maximal incentives to reveal whom they want to hook up with and to do that you need to insure them against common-knowledge rejections.
And that’s where Bang With Friends comes in.
Bang With Friends is a Facebook app, coded by a few college kids in a weekend, that facilitates no-risk hookups with people on your friends list. You say you’d like to bang them, and no one ever knows, unless they happen to say that they’d like to bang you, too.
Now this indeed takes care of one side of the incentive problem, but I worry about the other side. Suppose I want to know who wants to bang with me even if I don’t have the same lust for them. I can find out by putting all of my friends on my Down To Bang list. The only cost I pay for this information is that all of those who are down to bang with me will be told that I am down to bang with them. In some cases this could be lead to some embarrassment and awkwardness but I imagine some people would pay that price just to find out. And anticipating this possibility everyone is again reluctant to be truthful about who they do want to Bang for fear of being caught out this way.
One way to mitigate the problem is to replace the flat list with a ranking of your friends from most to least Bang-able, and then establish a hookup only with the friend who is highest on your ranking among those who want to Bang back. Then if you do decide to pad your list, you will put the reconnaissance Bangage low on your list. Of course this will allow you to find out those friends who put you highest on their ranking, but at least this is less information than you can get with the existing system.
Google discontinued their appointment slots feature of Google Calendar. I was using that to schedule meetings with students. It was really nice because I could just block out some time for meetings and send a link to students and they would just sign up for 30 minute slots in the block. But no more. Does anybody know of a good alternative?
Cheap Talk has turned 4 years old. In honor of that, I could tell you about how many of you read us, how many of you subscribe to us, which were the greatest among all the great articles we wrote last year, etc. but instead I’ll take this opportunity to do something I have been wanting to do for a while.
A very interesting side benefit of having a blog is seeing the search terms that lead people to us. Its a fun game trying to figure out which post Google sent them to when they searched for terms like “students can lie to teachers very easily” but more than that, as the range of topics we have covered gets wider and wider just reading down the list of search terms each day starts to look like pure poetry.
So I decided to compose a poem entirely out of search phrases and as my fourth birthday present to myself I am going to make you read it. It is a testament to the power of the Internet that for each and every line below there was someone who, in a quest for knowledge, typed it into Google and Google dutifully led them to our blog.
For the best effect I recommend reading this poem in your best mental Christopher Walken voice.
Feral Dogs in Tampa
I like bareback sex with hookers
Explaining infinity to children,
The god in heaven
Serving GuinnessStatistically birthdays increase your age
What is there to do?
Remember abstract things
Courtney Conklin KnappLow hanging balls
Kink on demand,
Pile driver sex
I am tired of cohabitationYou are nothing
Empty plate with crumbs,
Playing with yourself in public
When will the Devil talk to you?Novel figure skates,
Who invented sarcasm,
Orthogonally-minded,
Try to arrange a meetingFuyuh.

Good grammar makes for bad passwords:
[…]there’s an Achilles’ heel in creating phrase-based passwords. It’s the fact that most English speakers will craft phrases that make sense.
Ashwini Rao and Gananand Kini at Carnegie Mellon and Birenda Jha at MIT have developed proof-of-concept password-cracking software that takes advantage of that weakness. It cracks long passwords, and beats existing cracking software, simply by following rules of English grammar.
“Using an analytical model based on parts-of-speech tagging, we show that the decrease in search space due to the presence of grammatical structures can be as high as 50 percent,” the researchers write in their paper.
Bad grammar makes for good passwords:
Instead, get creative. Try poor grammar and spelling, as in “de whippoorsnapper sashay sideway,” or get completely silly, as in “flipper flopper fliddle fladdle.”
It doesn’t matter how correct it is, as long as you can easily remember it.

Its here. I like the purpose, as given on the masthead:
This blog is to help me remember stories and papers and provide ideas for students taking the Behavioral and Experimental class. It will focus on behavioral and experimental economics, with the occasional gender story.
Most of the posts are indeed links to papers with quotes from abstracts, but I enjoyed this one departure from normal programming
One of my colleagues talked about a (not very inspired) way to do research, which he adequately describes as keyword research (and which he denounces whole heartily). The idea is the following, which seems to work very well for theory papers: Take a bunch of keywords, select a few, check if a paper has been written if so, try again…
In that spirit, I came across the following blogpost: Sociology title Generator
Bearskin bow: Mobius.
With social networking you are now exposed to so many different voices in rapid succession. Each one is monotonous as an individual but individual voices arrive too infrequently for you notice that, all you see is the endless variety of people saying and thinking things that you can never think or say. It seems like the everyone in the world is more creative than one-dimensional you.
Its called Nostra Culpa and its a 16 minute 2 act opera dramatizing the exchange on Twitter between Paul Krugman and Estonian President Toomas Ilves about that country’s austerity program. Robert Siegel interviewed the librettist and composer on NPR yesterday:
SIEGEL: I would sort of have expected you to have written this for a tenor and a baritone. But unexpectedly, for me at least, the two characters – Paul Krugman and President Ilves of Estonia – are both sung by the same mezzo-soprano.
BIRMAN: Right. Well, the mezzo-soprano is somebody I’ve worked with before and she’s, I think, one of the greatest talents in Estonia as a dramatic singer. And my idea – my sort of inspiration to set these words was not so much to make some kind of argument, but to have the singer portray the people themselves who are stuck in this – between these two sides.
SIEGEL: Now, one writer observed that the entire exchange between Krugman and Ilves consisted of a 70-word blog post with chart, and then four tweets. Puccini had a lot more to work with when he sat down to write “Tosca,” let’s say.
BIRMAN: Well, one could write an opera, a full-length two-hour opera, using just this content, in my opinion. Because, in a way, why is the story interesting? To me it’s interesting because we have been discussing this ever since 2008, 2009 – what to do and how to get out of this, and we’re still not out. And the story is being written as we go.
The opera has its debut on April 7 in Estonia.
My academic home page (http://faculty.wcas.northwestern.edu/~jel292/) is looking outdated. I need something new and a little more professional. Do you know anybody who designs websites for academics? Could you recommend anyone? An example of their work would be helpful.
Meanwhile here’s The Bad Plus playing with Bill Frisell at Newport. Amazing stuff.
All working for tech companies and all profiled in this article in The Economist.
ON THE face of it, economics has had a dreadful decade: it offered no prediction of the subprime or euro crises, and only bitter arguments over how to solve them. But alongside these failures, a small group of the world’s top microeconomists are quietly revolutionising the discipline. Working for big technology firms such as Google, Microsoft and eBay, they are changing the way business decisions are made and markets work.
Announced yesterday. The main points seem to be: enrollment for credit, a coalition of schools merging curriculum in some way, and some kind of real-time virtual classroom.
“Students from all over the country, or even from abroad, will be able to attend these online classes in real time — classes of about 15 to 20 students taught by professors at some of the nation’s leading universities,” said Daniel Linzer, Northwestern University provost.
Besides Northwestern, consortium members include Brandeis University, Duke University, Emory University, The University of North Carolina at Chapel Hill, University of Notre Dame, University of Rochester, Vanderbilt University, Wake Forest University and Washington University in St. Louis.
“These courses will expand curricular options for students and will enable consortium schools to work collaboratively to develop the most innovative and successful ways to utilize new learning technologies,” Northwestern Provost Linzer said.
Initial Semester Online courses will feature primarily the same faculty and curricula as their brick-and-mortar counterparts, with additional courses designed for the online format to be included in the future. Through a state-of-the-art virtual classroom, students will participate in discussions and exercises, attend lectures and collaborate with peers while guided by renowned professors — engaging in as close to the on-campus class experience that is currently possible online.
Beginning in the fall of 2013, Semester Online will be available to academically qualified students attending consortium schools as well as other top schools across the country. Information about Semester Online courses and the application process will be available in early 2013. The consortium anticipates adding a small number of institutions prior to next year’s launch.
The website for Semester Online is back there.
- Is it that women like to socialize more than men do or is it that everyone, men and women alike, prefers to socialize with women?
- A great way to test for strategic effort in sports would be to measure the decibel level of Maria Sharapova’s grunts at various points in a match.
- If you are browsing the New York Times and you are over your article limit for the month, hit the stop button just after the page renders but before the browser has a chance to load the “Please subscribe” overlay. This is easy on slow browsers like your phone.
- Given the Archimedes Principle why do we think that the sea level will rise when the Polar Caps melt?
Nate Silver’s 538 Election Forecast has consistently given Obama a higher re-election probability than InTrade does. The 538 forecast is based on estimating vote probabilities from State polls and simulating the Electoral College. InTrade is just a betting market where Obama’s re-election probability is equated with the market price of a security that pays off $1 in the event that Obama wins. How can we decide which is the more accurate forecast? When you log on in the morning and see that InTrade has Obama at 70% and Nate Silver has him at 80%, on what basis can we say that one of them is right and the other is wrong?
At a philosophical level we can say they are both wrong. Either Obama is going to win or Romney is going to win so the only correct forecast would give one of them 100% chance of winning. Slightly less philosophically, is there any interpretation of the concept of “probability” relative to which we can judge these two forecasting methods?
One way is to define probability simply as the odds at which you would be indifferent between betting one way or the other. InTrade is meant to be the ideal forecast according to this interpretation because of course you can actually go and bet there. If you are not there betting right now then we can infer you agree with the odds. One reason among many to be unsatisfied with this conclusion is that there are many other betting sites where the odds are dramatically different.
Then there’s the Frequentist interpretation. Based on all the information we have (especially polls) if this situation were repeated in a series of similar elections, what fraction of those elections would eventually come out in Obama’s favor? Nate Silver is trying to do something like this. But there is never going to be anything close to enough data to be able to test whether his model is getting the right frequency.
Nevertheless, there is a way to assess any forecasting method that doesn’t require you to buy into any particular interpretation of probability. Because however you interpret it, mathematically a probability estimate has to satisfy some basic laws. For a process like an election where information arrives over time about an event to be resolved later, one of these laws is called the Martingale property.
The Martingale property says this. Suppose you checked the forecast in the morning and it said Obama 70%. And then you sit down to check the updated forecast in the evening. Before you check you don’t know exactly how its going to be revised. Sometimes it gets revised upward, sometimes downard. Soometimes by a lot, sometimes just a little. But if the forecast is truly a probability then on average it doesn’t change at all. Statistically we should see that the average forecast in the evening equals the actual forecast in the morning.
We can be pretty confident that Nate Silver’s 538 forecast would fail this test. That’s because of how it works. It looks at polls and estimates vote shares based on that information. It is an entirely backward-looking model. If there are any trends in the polls that are discernible from data these trends will systematically reflect themselves in the daily forecast and that would violate the Martingale property. (There is some trendline adjustment but this is used to adjust older polls to estimate current standing. And there is some forward looking adjustment but this focuses on undecided voters and is based on general trends. The full methodology is described here.)
In order to avoid this problem, Nate Silver would have to do the following. Each day prior to the election his model should forecast what the model is going to say tomorrow, based on all of the available information today (think about that for a moment.) He is surely not doing that.
So 70% is not a probability no matter how you prefer to interpret that word. What does it mean then? Mechanically speaking its the number that comes out of a formula that combines a large body of recent polling data in complicated ways. It is probably monotonic in the sense that when the average poll is more favorable for Obama then a higher number comes out. That makes it a useful summary statistic. It means that if today his number is 70% and yesterday it was 69% you can logically conclude that his polls have gotten better in some aggregate sense.
But to really make the point about the difference between a simple barometer like that and a true probability, imagine taking Nate Silver’s forecast, writing it as a decimal (70% = 0.7) and then squaring it. You still get a “percentage,” but its a completely different number. Still its a perfectly valid barometer: its monotonic. By contrast, for a probability the actual number has meaning beyond the fact that it goes up or down.
What about InTrade? Well, if the market it efficient then it must be a Martingale. If not, then it would be possible to predict the day-to-day drift in the share price and earn arbitrage profits. On the other hand the market is clearly not efficient because the profits from arbitraging the different prices at BetFair and InTrade have been sitting there on the table for weeks.
Micropayments haven’t materialized. My guess is that’s because of a combination of two reasons. First, there are the technological/network externality barriers. Nobody as of yet has put forth a system for micropayments that is easy and compelling enough to spur widespread adoption.
The second reason is that micropayments may not actually be the most efficient way to achieve their purpose. A monetary payment is a one-to-one transfer of value from payor to payee. Right now many of the online transactions that micropayments would facilitate are actually financed with a more efficient means of payment. Advertisements are the best example. You want to watch a video on YouTube, you have to watch a little bit of an ad first.
This is a transfer of value: you lose some time, the advertiser gains your attention. But this transfer is not one-for-one because your opportunity cost of time is not identically equal to the value to the advertiser of your attention. And given the widespread use of advertisements in markets where monetary payments are possible, we can infer that this transfer is actually positive-sum. That is, the cost of your time is lower than the value of capturing your attention.
Microbarter is more efficient than micropayment. So we should expect to see even more of it. And we should expect that even more efficient forms of microbarter will appear. And indeed we soon will. Google has apparently figured out that information can be an even more efficient currency than attention:
Eighteen months ago — under non disclosure — Google showed publishers a new transaction system for inexpensive products such as newspaper articles. It worked like this: to gain access to a web site, the user is asked to participate to a short consumer research session. A single question, a set of images leading to a quick choice.
Once you think in terms of microbarter and positive-sum transactions there are probably many more ideas you could come up with. But a few questions too. Why is there not already a market which enables you to sell your valuable asset (attention, information etc) for money? After all, if it could be monetized and the market is competitive then the usual arguments will imply that at the margin the exchange will be zero-sum and the rationale for barter disappears.
(Ghutrah grip: Mallesh Pai)
Have you been following the Jonah Lehrer self-plagiarism flap? Here’s a backgrounder.
At a superficial level this is an absurdity. Recycling an idea is good if it speeds up the spread of the idea. Plagiarism is an offense only if it harms the original creator. If Jonah Lehrer is the original creator then whatever harm he is causing himself (i.e. none) he fully internalizes. No exernalities here, move on. You get the sense that journalists are mindlessly misapplying a norm they apparently don’t fully understand.
But at a level deeper, Jonah Lehrer’s self-plagiarism is basically the same as plagiarism. Because he recycled material he wrote for one publisher into new material written for a different publisher. The original publisher had a role in the creative process. They selected Jonah Lehrer as an author, they edited and ultimately approved his work. They invested in it. The new publisher probably has an implicit agreement with other publishers not to infringe on their creative output. Because Jonah Lehrer did not inform the new publisher of his self-plagiarism he led them to violate that agreement.
But let’s go the final level deeper. When we recognize the equivalence what we really should conclude is that policing plagiarism is just as absurd as policing self-plagiarism. Ideas are useless if they are not spread and the value of an idea is independent of who created it. To put a halt to the spread of an idea just because of a dispute about somebody’s long-ago sunk cost is a pure social waste.
This is a screenshot from an espn.com webstreaming replay of the French Open match between Maria Sharapova and Klara Zakapalova. As you can see Sharapova won the first set and now they are locked in a tight second set. But hmmm… something tells me that Zakapalova will be able to push it to three sets…

Courtesy of Emir Kamenica.
Here are the paths between me and Lones Smith. Some other numbers:
- My Erdos number is 4
- My Ken Arrow number is 5
- My Tyler Cowen number is 4. (I am not sure I believe all of these paths but some of them are true and interesting.)
- My Barack Hussein Obama number is 4 and the shortest path goes through Hilary Clinton.
Twitter users turned Sunday’s French presidential election into a battle between a green Hungarian wine and a red Dutch cheese in a bid to get round tough laws banning result predictions.
The #RadioLondres hashtag was the top France trend on Twitter during the first-round presidential vote, in homage to World War II codes broadcast to Resistance fighters in Nazi-occupied France from the BBC in London.
But French citizens have written a new codebook in a subversive bid to get round laws that mean anyone announcing vote predictions before polls closed at 8:00 pm (1800 GMT) could be fined up to 75,000 euros (100,000 dollars).
“Tune in to #RadioLondres so as not to know the figures we don’t want to know before 8:00 pm,” said one ironic tweet.
“Dutch cheese at 27 euros, Tokai wine at 25 euros,” read one tweet as poll percentage predictions were published abroad.
The thing is, this would still be prosecuted if perpetrated by broadcast media. So it wasn’t the code per se that allowed them to circumvent the law. So the questions are:
- Why is an in-spirit violation not prosecuted when carried out in a decentralized communication network?
- Would just nakedly forecasting the outcome also escape prosecution if done on Twitter? (As opposed to the usual things people nakedly do on Twitter.)
The pointer was from @handeh.
Twitter has finally acknowledged a long-suspected bug that makes users automatically unfollow accounts for no apparent reason, and now that it’s working on a fix, many would rather keep the bug to cover the awkwardness of manually unfollowing people. Time to admit you’re just sick of your friends’ updates, folks.
Of course, Twitter power users like Reuters’ Anthony De Rosa don’t really want to automatically lose followers, but it’s sort of funny for him to tweet “one benefit of the unfollow bug is it gives me an excuse if someone gets upset i unfollowed them.” De Rosa’s far from the only one. It seems likehundreds reacted with the same sentiment on hearing the news. That’s because it’s true that sometimes you keep following some idiot just because you don’t want the drama of dropping them. Look at how many people publiclycomplain about losing a follower. Well, tweeters, it’s time for us to take responsibility for our actions just a little bit more. Take a cue from The Awl’s Choire Sicha and embrace the hate.
The link came from Courtney Conklin Knapp, who I believe still follows me but I can’t be sure.
- If you have a blog and you write about potential research questions, write the question out clearly but give a wrong answer. This solves the problem I raised here.
- When I send an email to two people I feel bad for the person whose name I address second (“Dear Joe and Jane”) so I put it twice to make it up to them (“Dear Joe and Jane and Jane.”)
- If you have a rich country and a poor country and their economies are growing at the same rate you will nevertheless have rising inequality over time simply because, as is well documented, the poor have more kids.
- Are there arguments against covering contraception under health insurance that don’t also apply to covering vaccines?
- The most interesting news is either so juicy that the source wants it kept private or so important that the source wants to make it public. This is why Facebook is an inferior form of communication: as neither private nor fully public it is an interior minimum.
Email is the superior form of communication as I have argued a few times before, but it can sure aggravate your self-control problems. I am here to help you with that.
As you sit in your office working, reading, etc., the random email arrival process is ticking along inside your computer. As time passes it becomes more and more likely that there is email waiting for you and if you can’t resist the temptation you are going to waste a lot of time checking to see what’s in your inbox. And it’s not just the time spent checking because once you set down your book and start checking you won’t be able to stop yourself from browsing the web a little, checking twitter, auto-googling, maybe even sending out an email which will eventually be replied to thereby sealing your fate for the next round of checking.
One thing you can do is activate your audible email notification so that whenever an email arrives you will be immediately alerted. Now I hear you saying “the problem is my constantly checking email, how in the world am i going to solve that by setting up a system that tells me when email arrives? Without the notification system at least I have some chance of resisting the temptation because I never know for sure that an email is waiting.”
Yes, but it cuts two ways. When the notification system is activated you are immediately informed when an email arrives and you are correct that such information is going to overwhelm your resistance and you will wind up checking. But, what you get in return is knowing for certain when there is no email waiting for you.
It’s a very interesting tradeoff and one we can precisely characterize with a little mathematics. But before we go into it, I want you to ask yourself a question and note the answer before reading on. On a typical day if you are deciding whether to check your inbox, suppose that the probability is p that you have new mail. What p is going to get you to get up and check? We know that you’re going to check if p=1 (indeed that’s what your mailbeep does, it puts you at p=1.) And we know that you are not going to check when p=0. What I want to know is what is the threshold above which its sufficiently likely that you will check and below which is sufficiently unlikely so you’ll keep on reading? Important: I am not asking you what policy you would ideally stick to if you could control your temptation, I am asking you to be honest about your willpower.
Ok, now that you’ve got your answer let’s figure out whether you should use your mailbeep or not. The first thing to note is that the mail arrival process is a Poisson process: the probability that an email arrives in a given time interval is a function only of the length of time, and it is determined by the arrival rate parameter r. If you receive a lot of email you have a large r, if the average time spent between arrivals is longer you have a small r. In a Poisson process, the elapsed time before the next email arrives is a random variable and it is governed by the exponential distribution.
Let’s think about what will happen if you turn on your mail notifier. Then whenever there is silence you know for sure there is no email, p=0 and you can comfortably go on working temptation free. This state of affairs is going to continue until the first beep at which point you know for sure you have mail (p=1) and you will check it. This is a random amount of time, but one way to measure how much time you waste with the notifier on is to ask how much time on average will you be able to remain working before the next time you check. And the answer to that is the expected duration of the exponential waiting time of the Poisson process. It has a simple expression:
Expected time between checks with notifier on =
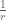
Now let’s analyze your behavior when the notifier is turned off. Things are very different now. You are never going to know for sure whether you have mail but as more and more time passes you are going to become increasingly confident that some mail is waiting, and therefore increasingly tempted to check. So, instead of p lingering at 0 for a spell before jumping up to 1 now it’s going to begin at 0 starting from the very last moment you previously checked but then steadily and continuously rise over time converging to, but never actually equaling 1. The exponential distribution gives the following formula for the probability at time T that a new email has arrived.
Probability that email arrives at or before a given time T =
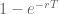
Now I asked you what is the p* above which you cannot resist the temptation to check email. When you have your notifier turned off and you are sitting there reading, p will be gradually rising up to the point where it exceeds p* and right at that instant you will check. Unlike with the notification system this is a deterministic length of time, and we can use the above formula to solve for the deterministic time T at which you succumb to temptation. It’s given by
Time between checks when the notifier is off =

And when we compare the two waiting times we see that, perhaps surprisingly, the comparison does not depend on your arrival rate r (it appears in the numerator of both expressions so it will cancel out when we compare them.) That’s why I didn’t ask you that, it won’t affect my prescription (although if you receive as much email as I do, you have to factor in that the mail beep turns into a Geiger counter and that may or may not be desirable for other reasons.) All that matters is your p* and by equating the two waiting times we can solve for the crucial cutoff value that determines whether you should use the beeper or not.
The beep increases your productivity iff your p* is smaller than
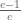
This is about .63 so if your p* is less than .63 meaning that your temptation is so strong that you cannot resist checking any time you think that there is at least a 63% chance there is new mail waiting for you then you should turn on your new mail alert. If you are less prone to temptation then yes you should silence it. This is life-changing advice and you are welcome.
Now, for the vapor mill and feeling free to profit, we do not content ourselves with these two extreme mechanisms. We can theorize what the optimal notification system would be. It’s very counterintuitive to think that you could somehow “trick” yourself into waiting longer for email but in fact even though you are the perfectly-rational-despite-being-highly-prone-to-temptation person that you are, you can. I give one simple mechanism, and some open questions below the fold.
Here for your amusement is a collection of Facebook postings by people who don’t seem to understand that The Onion is fake news. Now, remember that The Onion is satire. And a piece of satire works best when it bears some resemblance to the object of satire. If a story in The Onion were not believed to be true by anybody then that would be a clear indication that it was poor satire. In other words, the credibility of a story in The Onion is optimally chosen so that inevitably a minimal fraction of people will believe it.
So it should not be amusing that some people fall for stories in The Onion, anymore than it is amusing that the Sun rises on Wednesdays. What would be amusing is finding out exactly who it is that lives in that tail of the gullibility distribution. However the web site is anonymized. So to me what is amusing about all of this is discovering how many exactly which people find this site amusing.
Chris Ziegler, retweeted by Tyler Cowen
imagine sitting down at a desk while 250 people line up and tell you, one by one, that kim jong-il has died. that’s twitter.
To which I reply: imagine logging into Twitter and 250 people line up to tell you that Kim Jon-Il has died, and they can do it using as many characters as they want, and believe me these guys can use a lot of characters, and not only that but after they are done telling you, they are standing there in front of you and you have to have conversation with them and then find some polite way to say get out of here, i need to get some work done. That’s working in an office.
Forget about Twitter as a medium for organizing protests, it is surprisingly effective as an actual protest forum. Yesterday there was a story on NPR about a flurry of protest tweets that, within just hours, got JCPenney to remove from their racks a controversial t-shirt with the slogan “I’m too pretty to do homework so I have my brother do it for me.” (I am not 100% sure but I think the parents were worried about the message this was sending to boys. Boys can be pretty too and they shouldn’t always be doing so much homework.)
Electronic communications and social networking change the power structure of protests. One subtle reason is that the act of listening to the protest is no longer public and verifiable. The organization that you are protesting against would like to commit not to listen to your protest. If we believe that there is no way to get JCPenney’s ear then no matter how much we care about boys’ self esteem we waste our effort on a futile protest. In the old days, with the exception of protests so vocal that they make the evening news, this commitment was credible. Just don’t give out any public channel through which to express your protest.
Now the channel is already there. But more importantly, the act of listening to the protest is private and not verifiable. It is impossible to commit not to listen to protests on Twitter. JCPenney would like to announce to the world that no matter how much we protest on Twitter they are just not paying attention, so don’t bother. But even if they believed that announcement worked, they would still have an incentive to monitor #JCPenney hashtags on Twitter just in case some protest happened to break out. We all know that so we don’t believe them when they say they aren’t listening.
So social media change the balance of power of protests because they give the protesters the first-mover advantage.
Beginning in February of 2012 Stanford economist Matt Jackson and computer scientist Yoav Shoham will be offering an online course in game theory. 2 hours of video lectures will be posted each week online and there will be a forum to ask questions of the instructors. Here is their introductory video.
The website where you can sign up for the course is here. Northwestern/Kellogg should do stuff like this.
I stopped following Justin Wolfers on Twitter. Not because I don’t want his tweets, they are great, but because everyone I follow also follows Justin. They all retweet his best tweets and I see those so I am not losing anything.
Which made me wonder how increasing density of the social network affects how informed people are. Suppose you are on a desert island but a special desert island which receives postal deliveries. You can get informed by subscribing to newspapers but you can’t talk to anybody. As long as the value v of being informed exceeds the cost c you will subscribe.
Compare that to an individual in a dense social network who can either pay for a subscription or wait around for his friends to get informed and find out from them. It won’t be an equilibrium for everybody to subscribe. You would do better by saving the cost and learning from your friends. Likewise it can’t be that nobody subscribes.
Instead in equilibrium everybody will subscribe with some probability between 0 and 1. And there is a simple way to compute that probability. In such an equilibrium you must be indifferent between subscribing and not subscribing. So the total probability that at least one of your friends subscribes must be the q that satisfies vq = v – c. The probability of any one individual subscribing must of course be lower than q since q is the total probability that at least one subscribes. So if you have n friends, then they each subscribe with the probability p(n) satisfiying 1 – [1 – p(n)]^n = q.
(Let’s pause while the network theorists all rush out of the room to their whiteboards to solve the combinatorial problem of making these balance out when you have an arbitrary network with different nodes having a different number of neighbors.)
This has some interesting implications. Suppose that the network is very dense so that everybody has many friends. Then everyone is less likely to subscribe. We only need a few people to be Justin Wolfers’ followers and retweet all of his best tweets. Formally, p(n) is decreasing in n.
That by itself is not such a bad thing. Even though each of your friends subscribes with a lower probability, on the positive side you have more friends from whom you can indirectly get informed. The net effect could be that you are more likely to be informed.
But in fact the net effect is that a denser network means that people are on average less informed, not more. Because if the network density is such that everyone has (on average) n friends, then everybody subscribes with probability p(n) and then the probability that you learn the information is q + (1-q)p(n). (With probability q one of your friends subscribes and you learn from them, and if you don’t learn from a friend then you become informed only if you have subscribed yourself which you do with probability p(n).) Since p(n) gets smaller with n, so does the total probability that you are informed.
Another way of saying this is that, contrary to intuition, if you compare two otherwise similar people, those who are well connected within the network have a tendency to be less informed than those who are in a relatively isolated part of the network.
All of this is based on a symmetric equilibrium. So one way to think about this is as a theory for why we see hierachies in information transmission, as represented by an asymmetric equilibrium in which some people subscribe for sure and others are certain not to. At the top of the hierarchy there is Justin Wolfers. Just below him we have a few people who follow him. They have a strict incentive to follow him because so few others follow him that the only way to be sure to get his tweets is to follow him directly. Below them is a mass of people who follow these “retailers.”
