
You are currently browsing the tag archive for the ‘computers’ tag.
Here’s the explainer.
Remember how baffled Kasparov was about Deep Blue’s play in their famous match? It gets interesting.
Earlier this year, IBM celebrated the 15-year anniversary of its supercomputer Deep Blue beating chess champion Garry Kasparov. According to a new book, however, it may have been an accidental glitch rather than computing firepower that gave Deep Blue the win.
At the Washington Post, Brad Plumer highlights a passage from Nate Silver’s The Signal and the Noise. Silver interviewed Murray Campbell, a computer scientist that worked on Deep Blue, who explained that during the 1997 tournament the supercomputer suffered from a bug in the first game. Unable to pick a strategic move because of the glitch, it resorted to its fall-back mechanism: choosing a play at random. “A bug occurred in the game and it may have made Kasparov misunderstand the capabilities of Deep Blue,” Campbell tells Silver in the book. “He didn’t come up with the theory that the move it played was a bug.”
As Silver explains it, Kasparov may have taken his own inability to understand the logic of Deep Blue’s buggy move as a sign of the computer’s superiority. Sure enough, Kasparov began having difficulty in the second game of the tournament — and Deep Blue ended up winning in the end.
Visor volley: Mallesh Pai.
This guy built an actual Turing machine.
My goal in building this project was to create a machine that embodied the classic look and feel of the machine presented in Turing’s paper. I wanted to build a machine that would be immediately recognizable as a Turing machine to someone familiar with Turing’s work.
The video is precious.
Email is the superior form of communication as I have argued a few times before, but it can sure aggravate your self-control problems. I am here to help you with that.
As you sit in your office working, reading, etc., the random email arrival process is ticking along inside your computer. As time passes it becomes more and more likely that there is email waiting for you and if you can’t resist the temptation you are going to waste a lot of time checking to see what’s in your inbox. And it’s not just the time spent checking because once you set down your book and start checking you won’t be able to stop yourself from browsing the web a little, checking twitter, auto-googling, maybe even sending out an email which will eventually be replied to thereby sealing your fate for the next round of checking.
One thing you can do is activate your audible email notification so that whenever an email arrives you will be immediately alerted. Now I hear you saying “the problem is my constantly checking email, how in the world am i going to solve that by setting up a system that tells me when email arrives? Without the notification system at least I have some chance of resisting the temptation because I never know for sure that an email is waiting.”
Yes, but it cuts two ways. When the notification system is activated you are immediately informed when an email arrives and you are correct that such information is going to overwhelm your resistance and you will wind up checking. But, what you get in return is knowing for certain when there is no email waiting for you.
It’s a very interesting tradeoff and one we can precisely characterize with a little mathematics. But before we go into it, I want you to ask yourself a question and note the answer before reading on. On a typical day if you are deciding whether to check your inbox, suppose that the probability is p that you have new mail. What p is going to get you to get up and check? We know that you’re going to check if p=1 (indeed that’s what your mailbeep does, it puts you at p=1.) And we know that you are not going to check when p=0. What I want to know is what is the threshold above which its sufficiently likely that you will check and below which is sufficiently unlikely so you’ll keep on reading? Important: I am not asking you what policy you would ideally stick to if you could control your temptation, I am asking you to be honest about your willpower.
Ok, now that you’ve got your answer let’s figure out whether you should use your mailbeep or not. The first thing to note is that the mail arrival process is a Poisson process: the probability that an email arrives in a given time interval is a function only of the length of time, and it is determined by the arrival rate parameter r. If you receive a lot of email you have a large r, if the average time spent between arrivals is longer you have a small r. In a Poisson process, the elapsed time before the next email arrives is a random variable and it is governed by the exponential distribution.
Let’s think about what will happen if you turn on your mail notifier. Then whenever there is silence you know for sure there is no email, p=0 and you can comfortably go on working temptation free. This state of affairs is going to continue until the first beep at which point you know for sure you have mail (p=1) and you will check it. This is a random amount of time, but one way to measure how much time you waste with the notifier on is to ask how much time on average will you be able to remain working before the next time you check. And the answer to that is the expected duration of the exponential waiting time of the Poisson process. It has a simple expression:
Expected time between checks with notifier on =
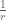
Now let’s analyze your behavior when the notifier is turned off. Things are very different now. You are never going to know for sure whether you have mail but as more and more time passes you are going to become increasingly confident that some mail is waiting, and therefore increasingly tempted to check. So, instead of p lingering at 0 for a spell before jumping up to 1 now it’s going to begin at 0 starting from the very last moment you previously checked but then steadily and continuously rise over time converging to, but never actually equaling 1. The exponential distribution gives the following formula for the probability at time T that a new email has arrived.
Probability that email arrives at or before a given time T =
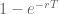
Now I asked you what is the p* above which you cannot resist the temptation to check email. When you have your notifier turned off and you are sitting there reading, p will be gradually rising up to the point where it exceeds p* and right at that instant you will check. Unlike with the notification system this is a deterministic length of time, and we can use the above formula to solve for the deterministic time T at which you succumb to temptation. It’s given by
Time between checks when the notifier is off =

And when we compare the two waiting times we see that, perhaps surprisingly, the comparison does not depend on your arrival rate r (it appears in the numerator of both expressions so it will cancel out when we compare them.) That’s why I didn’t ask you that, it won’t affect my prescription (although if you receive as much email as I do, you have to factor in that the mail beep turns into a Geiger counter and that may or may not be desirable for other reasons.) All that matters is your p* and by equating the two waiting times we can solve for the crucial cutoff value that determines whether you should use the beeper or not.
The beep increases your productivity iff your p* is smaller than
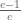
This is about .63 so if your p* is less than .63 meaning that your temptation is so strong that you cannot resist checking any time you think that there is at least a 63% chance there is new mail waiting for you then you should turn on your new mail alert. If you are less prone to temptation then yes you should silence it. This is life-changing advice and you are welcome.
Now, for the vapor mill and feeling free to profit, we do not content ourselves with these two extreme mechanisms. We can theorize what the optimal notification system would be. It’s very counterintuitive to think that you could somehow “trick” yourself into waiting longer for email but in fact even though you are the perfectly-rational-despite-being-highly-prone-to-temptation person that you are, you can. I give one simple mechanism, and some open questions below the fold.
Turing Test #N-1: detect sarcasm:
“Sarcasm, also called verbal irony, is the name given to speech bearing a semantic interpretation exactly opposite to its literal meaning.” With that in mind, they then focussed on 131 occurrences of the phrase“yeah right” in the ‘Switchboard’ and ‘Fisher’ recorded telephone conversation databases. Human listeners who sifted the data found that roughly 23% of the “yeah right”s which occurred were used in a recognisably sarcastic way. The lab’s computer algorithms were then ‘trained’ with two five-state Hidden Markov Models (HMM) and set to analyse the data – and the programmes performed relatively well, successfully flagging some 80% of the sarky “yeah right”s.
That’s pretty good, but I’ll wait around for the computers to pass the Nth and ultimate Turing Test: compose a joke that is actually funny.
Honestly if we had to rank tests of similarity to human interaction, I believe that composing original humor is probably the very last one computers will solve. (Restricting attention to the usual thought experiment where the subject you are interacting with is in another room and you have to judge whether it is a human or a computer just on the basis of text-based interaction.)
- Software agents are invading online poker sites and relieving the humans of their money.
- The New York Times web site will beat you at rock scissors paper because you are a predictable human. (mm: Courtney Conklin Knapp)
- Tyler Cowen and his computer make each other better at chess.
Following up on Tyler, the suggestion is that there are gains from specialization in computer/human partnerships. But it is not enough for Tyler and his computer to beat a computer. Could Tyler and another human player (of strength comparable to his computer partner) do even better?
Now it is interesting to observe that the other comparison is not possible. Would a team of two computers (with strengths comparable to Tyler and his machine) do even better? How would two computers make a team? If the two computers came up with different ideas how would they decide which one was better?
010101: I think we should play Re1. I rate it +.30
1110011: I considered that move and at 22 ply I rate it at +0.05, instead I suggest we sac the Knight.
010101: I considered that move and at 22 ply I rate it at -1.8.
1110011: Here take a look at my analysis.
010101: Yes I am aware of that sequence of moves, I already considered it. It’s worth +0.05.
1110011: No, +0.30
010101: No, +0.05
etc. Any protocol for deciding which is the right analysis should already have been programmed into the original software. Put differently, if there was a way to map the pair of evaluations (.3,.05) into a better evaluation y, then the position should already have been evaluated at y by each machine individually.
The only benefit of the two computers would be the deeper search in the same amount time. That is, a two computer team is just two parallel processers but exactly the same evaluation heuristic applied to the final position searched. In that sense the human’s unique ability is to understand when to switch heuristics. (But why can’t this understanding be programmed into software?)
Now you can add coffee stains to your LaTeX documents without wasting coffee:

Your readers will appreciate you saving them the effort. From the package documentation:
This package provides an essential feature to LATEX that has been missing for too long. It adds a coffee stain to your documents. A lot of time can be saved by printing stains directly on the page rather than adding it manually. You can choose from four different stain types:
1. 270◦ circle stain with two tiny splashes
2. 60◦ circle stain
3. two splashes with light colours
4. and a colourful twin splash.
Dunce Cap Doff: Jordi Soler.
The District of Columbia is testing a system to allow overseas military personnel submit absentee electronic ballots via the internet. Obviously security is a major concern and the followed a suggestion often made by the security community to open the system to the public and allow white-hat hackers to try and find exploits. Here is the account of one team who participated and found a vulnerability within 36 hours.
By formatting the string in a particular way, we could cause the server to execute commands on our behalf. For example, the filename “ballot.$(sleep 10)pdf” would cause the server to pause for ten seconds (executing the “sleep 10” command) before responding. In effect, this vulnerability allowed us to remotely log in to the server as a privileged user
As a result, deployment of the system has been delayed.
This is exactly the kind of open, public testing that many of us in the e-voting security community — including me — have been encouraging vendors and municipalities to conduct.
But it could have turned out differently. If a black-hat got there first, they could fix the vulnerability after first leaving themselves a backdoor. Then the test comes out looking like a success, it goes live, and …
The New York Post reports that the FTC and the Justice Department are deciding which of those two entities will conduct an inquiry into Apple’s ban on iPhone-iPad development using cross-platform tools such as Adobe’s Flash-to-iPhone.
An inquiry doesn’t necessarily mean action will be taken against Apple, which argues the rule is in place to ensure the quality of the apps it sells to customers. Typically, regulators initiate inquiries to determine whether a full-fledged investigation ought to be launched. If the inquiry escalates to an investigation, the agency handling the matter would issue Apple a subpoena seeking information about the policy.
An inquiry is harmless in theory, often a slippery slope in practice. While there is certainly much to complain about, the general principle of not meddling when the market is still in its fluid infancy is the dominant consideration here. Remember the Microsoft case?
When you are competing to be the dominant platform, compatibility is an important strategic variable. Generally if you are the upstart you want your platform to be compatible with the established one. This lowers users’ costs of trying yours out. Then of course when you become established, you want to keep your platform incompatible with any upstart.
Apple made a bold move last week in its bid to solidify the iPhone/iPad as the platform for mobile applications. Apple sneaked into its iPhone OS Developer’s agreement a new rule which will keep any apps out of its App Store that were developed using cross-platform tools. That is, if you write an application in Adobe’s Flash (the dominant web-based application platform) and produce an iPhone version of that app using Adobe’s portability tools, the iPhone platform is closed to you. Instead you must develop your app natively using Apple’s software development tools. This self-imposed-incompatibility shows that Apple believes that the iPhone will be the dominant platform and developers will prefer to invest in specializing in the iPhone rather than be left out in the cold.
Many commentators, while observing its double-edged nature, nevertheless conclude that on net this will be good for end users. Jon Gruber writes
Cross-platform software toolkits have never — ever — produced top-notch native apps for Apple platforms…
[P]erhaps iPhone users will be missing out on good apps that would have been released if not for this rule, but won’t now. I don’t think iPhone OS users are going to miss the sort of apps these cross-platform toolkits produce, though. My opinion is that iPhone users will be well-served by this rule. The App Store is not lacking for quantity of titles.
And Steve Jobs concurs.
We’ve been there before, and intermediate layers between the platform and the developer ultimately produces sub-standard apps and hinders the progress of the platform.
Think about it this way. Suppose you are writing an app for your own use and, all things considered, you find it most convenient to write in a portable framework and export a version for your iPhone. That option has just been taken away from you. (By the way, this thought experiment is not so hypothetical. Did you know that you must ask Apple for permission to distribute to yourself software that you wrote?) You will respond in one of two ways. Either you will incur the additional cost and write it using native Apple tools, or you will just give up.
There is no doubt that you will be happier ex post with the final product if you choose the former. But you could have done that voluntarily before and so you are certainly worse off on net. Now the “market” as a whole is just you divided into your two separate parts, developer and user. Ex post all parties will be happy with the apps they get, but this gain is necessarily outweighed by the loss from the apps they don’t get.
Is there any good argument why this should not be considered anti-competitive?
One case in which dropping copy protection improved sales.
It’s been 18 months since O’Reilly, the world’s largest publisher of tech books, stopped using DRM on its ebooks. In the intervening time, O’Reilly’s ebook sales have increased by 104 percent. Now, when you talk about ebooks and DRM, there’s always someone who’ll say, “But what about [textbooks|technical books|RPG manuals]? Their target audience is so wired and online, why wouldn’t they just copy the books without paying? They’ve all got the technical know-how.”So much for that theory.
More here.
Addendum: see the comments below for good reason to dismiss this particular datum.
You are late with a report and its not ready. Do you wrap it up and submit it or keep working until its ready? The longer it takes you the higher standard it will be judged by. Because if you needed the extra time it must be because its going to be extra good.
For some people the speed at which they come up with good ideas outpaces these rising expectations. Others are too slow. But its the fast ones who tend to be late. Because although expectations will be raised they will exceed those. The slow ones have to be early otherwise the wedge between expectations and their performance will explode and they will never find a good time to stop.
Compare Apple and Sony. Sony comes out with a new product every day. And they are never expected to be a big deal. Every single Apple release is a big deal. And highly anticipated. We knew Apple was working on a phone more than a year before the iPhone. It was known that tablet designs had been considered for years before the iPad. With every leak and every rumor that Steve Jobs was not yet happy, expectations were raised for whatever would eventually make it through that filter.
Dear TE referees. Nobody is paying attention to how late you are.
Computer scientists study game theory from the perspective of computability.
Daskalakis, working with Christos Papadimitriou of the University of California, Berkeley, and the University of Liverpool’s Paul Goldberg, has shown that for some games, the Nash equilibrium is so hard to calculate that all the computers in the world couldn’t find it in the lifetime of the universe. And in those cases, Daskalakis believes, human beings playing the game probably haven’t found it either.
Solving the n-body problem is beyond the capabilities of the world’s smartest mathematicians. How do those rocks-for-brains planets manage to do pull it off?
Mindhacks has an interesting article about the use of robots in war. We know the U.S. is using pilotless drones to attack suspected terrorists in the mountain range between Afghanistan and Pakistan. This can save lives and presumably there are technological capabilities that are impossible for a human to replicate. But the possibility of human error is replaced by the possibility of computer error and, Mindhacks points out, even lack of robot predictability.
I went to a military operations research conference to present at a game theory session. Two things surprised me. First, game theory has disappeared from the field. They remember Schelling but are unaware that anything has happened since the 1960s. Asymmetric information models are a huge surprise to them. Second, they are aware of computer games. They just want to simulate complex games and run them again and again to see what happens. Then, you don’t get any intuition for why some strategy works or does not work or really an intuition for the game as a whole. And what you put in is what you get out: if you did not out in an insurgency movement causing chaos then it’s not going to pop out. This is also a problem for an analytical approach where you may not incorporate key strategic considerations into the game. Cliched “Out-of the-Box” thinking is necessary. Even a Mac can’t do it.
So, as long as there is war, men will go to war and think about how to win wars.
(Hat tip: Jeff for pointing out article)
Apparently we have arrived at the long run and we are not dead.
Do you remember the Microsoft anti-trust case? The anti-trust division of the US Department of Justice sought the breakup of Microsoft for anti-competitive practices mostly centering around integrating Internet Explorer into the Windows operating system. In fact, an initial ruling found Microsoft in violation of an agreement not to tie new software products into Windows and mandated a breakup, separating the operating systems business from the software applications business. This ruling was overturned on appeal and evnetually the case was settled with an agreement that imposed no further restrictions on Microsoft’s ability to bundle software but did require Microsoft to share APIs with third-party developers for a 5 year period.
Today, all of the players in that case are mostly irrelevant. AOL, Netscape, Redhat. Java. Indeed, Microsoft itself is close to irrelevance in the sense that any attempt today at exploiting its operating system market power to extend its monopoly would cause at most a short-run adjustment period before it would be ignored.
Microsoft was arguing at the time that it was constantly innovating to maintain its market position and it was impossible to predict from where the next threat to its dominance would appear. Whether or not the first part of their claim was true, the second part certainly turned out to be so. It is hard to see a credible case that the Microsoft anti-trust investigation, trial, and settlement played anything more than a negligible role in bringing us to this point. Indeed the considerations there, focusing on the internals of the operating system and contracts with hardware manufacturers, are orthogonal to developments in the market since then. The operating system is a client and today clients are perfect substitutes. The rents go to servers and servers live on the internet unconstrained by any “platform” or “network effects”, indeed creating their own.
The lesson of this experience is that in a rapidly changing landscape, intervention can wait. Even intervention that looks urgent at the time. Almost certainly the unexpected will happen that will change everything.
Like most San Franciscans, Charles Pitts is wired. Mr. Pitts, who is 37 years old, has accounts on Facebook, MySpace and Twitter. He runs an Internet forum on Yahoo, reads news online and keeps in touch with friends via email. The tough part is managing this digital lifestyle from his residence under a highway bridge.
The article is here. Another highlight:
Michael Ross creates his own electricity, with a gas generator perched outside his yellow-and-blue tent. For a year, Mr. Ross has stood guard at a parking lot for construction equipment, under a deal with the owner. Mr. Ross figures he has been homeless for about 15 years, surviving on his Army pension.
Inside the tent, the taciturn 50-year-old has an HP laptop with a 17-inch screen and 320 gigabytes of data storage, as well as four extra hard drives that can hold another 1,000 gigabytes, the equivalent of 200 DVDs. Mr. Ross loves movies. He rents some from Netflix and Blockbuster online and downloads others over an Ethernet connection at the San Francisco public library.
Here is a new paper on the economics of open-source software by Michael Schwarz and Yuri Takhteyev. They approach the subject from an interesting angle. Most authors are focused on the question of why people contribute to open-source. Instead these authors point out that people contribute to all kinds of public goods all the time and there should be no surprise that people contribute to open-source software. Instead, the question should be why do contributions to open source software turn out to be so much more important than say, giving away free haircuts.
The answer lies in a key advantage open-source has over proprietary software. Imagine you are starting a business and you are considering adopting some proprietary software and this will require you to train your staff to use it and make other complementary investments that are specific to the software. You make yourself vulnerable to hold-up: when new versions of the software are released, the seller’s pricing will take advantage of your commitment to the software. Open source software is guaranteed to be free even after improvements are made so users can safely make complementary investments without fear of holdup.
The theory explains some interesting facts about the software market. For example, did you know that all major desktop programming languages have open source compilers? But there are no open source tools for developing games for consoles such as the X-box.
The paper outlines this theory and describes how it fits with the emergence of open source over the years. The detailed history alone is worth reading.
There was a story on NPR about a program in Texas to decentralize border patrol efforts. Texas sheriffs are webcasting their surveillance cameras to the website bluservo.net where private citizens can login, monitor the video stream and report any suspicious activity they see.
Putting aside the political dimension of this, I see it as an interesting case study in open-source security. In the realm of computer network security, there is a debate about openness vs “security by obscurity.” For example, we may debate whether an open-source operating system like Linux is more or less secure than closed-source Windows. On the one hand, the security measures are in plain view for all the black-hats to see and try to circumvent. On the other hand, the openness enables the enourmous community of white hats to fix whatever problems they find. Which effect dominates?
The Texas sheriffs apparently side with the open-source community on this one. They seem not to be worried that the black-hat coyotes will use these cameras to figure out where to cross the border without being seen.
