
You are currently browsing jeff’s articles.
Browser bookmarklet that inserts a real-time third-party auction into the checkout screen of an online retailer.
So here’s the basic premise behind Gilt-ii. Everyday at noon ET, Gilt releases daily price cuts on luxury goods. There are limited quantities of these goods, and most of these items become unavailable within in minutes fo the sale opening. That’s why many shoppers on the site put things in their cart, where they have ten minutes to decide if they want to purchase the item, even if they aren’t necessarily sold on the idea of buying the item.
Gilt-ii’s bookmarklet allows those who have the items in their carts to transform into risk-free auctioneers, selling items to any Gilt shoppers who are accessing a “Sold Out – Item in Members’ Carts” message. When a user running “Gilt-ii” opens their shopping cart, their items are automatically registered for auction and displayed to out of luck buyers in the “Gilt-ii Auctions” box right into the item details page. From the auctions box, buyers submit bids on their desired items. As bids are made, they are displayed to the auctioneers right inside their shopping cart — if they see a price that they like, they can accept the bid and Gilt-ii will automatically handle the money transfer between users and change the shipping information at check out to that of the bidder. Auctioneers spend nothing until someone agrees to purchase the item from them.
As a Gilt shopper, I have experienced the letdown of not being able to purchase a coveted item (at a pretty good deal) because I didn’t act fast enough or I wasn’t able to check the site exactly when the sale started. Not only does Gilt-ii give shoppers a chance to purchase these already sold items, but it gives other Gilt shoppers the opportunity to make a few bucks off of purchases on the site by auctioning off items.
Pith helmet pitch: Mallesh Pai
Andrew Caplin told us about a new experiment that adds to the debate about “nudges.”
We have initiated experiments to study this tradeoff experimentally in a setting where imperfect perception seems highly likely and choice quality is easy to measure. In each round, subjects are presented with three options, each of which is composed of 20 numbers. The value of each option is the sum of the 20 numbers, and subjects are incentivized to select the object with the highest value. In the baseline treatment (“33%, 33%, 33%”), subjects were informed that all three options were equally likely to be the highest valued option, but in two other treatments, they were nudged towards the first option. In one of the nudge treatments (“40%, 30%, 30%”), subject were informed that the first option was 40% likely to be the highest valued option (the other two were both 30% likely). In the other nudge treament (“45%, 27.5%, 27.5%”), subjects were told that the first option was 45% likely to be the highest valued option (the other two were both 27.5% likely). Subjects completed 12 rounds of each treatment, which were presented in a random order.
The subjects got the best option only 54% of the time revealing that effort was required to add up all 20 numbers three times to find the largest sum. The nudges gave them hints but notice that the hints also lower the return to search effort. So in theory there will be both income and substitution effects. And in the experiment you see evidence of both. Their choices reveal that they utilized the hints: they more often chose the highlighted alternative. But, the interesting finding is that their chances of getting the best alternative did not increase. In essence, the hint perfectly crowded out their own search effort.
You could take a pessimistic view based on this: nudges don’t improve outcomes, they just make people lazier. But in fact the experiment suggests a nuanced interpretation of nudges. Even if we don’t see any evidence that, say published calorie counts improve the quality of decisions, that doesn’t imply that they have no welfare effects. Information is a fungible resource. If you give people information, they can save the effort of gathering it themselves. Given that information is a public good, these are potentially large welfare gains that would be hard to measure directly.
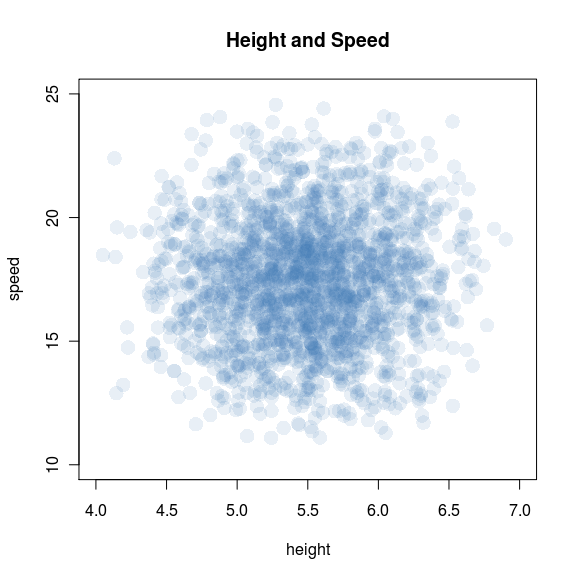
I once wrote about height and speed in tennis arguing that negative correlation appears at the highest level simply because they are substitutes and the athletes are selected to be the very best. At the blog MickeyMouseModels.blogspot.com, there is a post which shows very nicely the effect using simulated data. Quoting:
Suppose that, in the general population, the distribution of height and speed looks roughly like this:
Where did I get this data? It’s entirely hypothetical. I made it up! That said, I did try to keep it semi-realistic: the heights are generated as H = 4 + U1 + U2 + U3 feet, where the U are independently uniform on (0, 1); the result is a bell curve on (4, 7) feet, which I prefer to the (-Inf, +Inf) of an actual normal distribution. (I’ve created something similar to the N=3 frame in this animation.)
The next step is to give individuals a maximum footspeed S = 10 + U4 + U5 + U6 mph, with the U independently uniform on (0, 5). By construction, speed is independent from height, and falls more or less in a bell curve from 10 to 25 mph. Fun anecdote: my population is too slow to include Usain Bolt, whose top footspeed is close to 28 mph.
Back to tennis. Let’s imagine that tennis ability increases with both height and speed — and, moreover, that those two attributes are substitutable: if you’re short (and have a weak serve), you can make up for it by being fast. With that in mind, let’s revisit the scatterplot:
There it is: height and speed are independent in the general population, but very much dependent — and negatively correlated — among tennis players. The plot really drives the point home: top athletes will be either very tall, very fast, or nearly both; and excluding everyone else creates a downward slope.


That was the title of a very interesting talk at the Biology and Economics conference I attended over the weekend at USC. The authors are Juan Carillo, Isabelle Brocas and Ricardo Alonso. It’s basically a model of how multitasking is accomplished when different modules in the brain are responsible for specialized tasks and those modules require scarce resources like oxygen in order to do their job. (I cannot find a copy of the paper online.)
The brain is modeled as a kludgy organization. Imagine that the listening-to-your-wife division and the watching-the-French-Open division of YourBrainINC operate independently of one another and care about nothing but completing their individual tasks. What happens when both tasks are presented at the same time? In the model there is a central administrator in charge of deciding how to ration energy between the two divisions. What makes this non-trivial is that only the individual divisions know how much juice they are going to need based on the level of difficulty of this particular instance of the task.
Here’s the key perspective of the model. It is assumed that the divisions are greedy: they want all the resources they need to accomplish their task and only the central administrator internalizes the tradeoffs across the two tasks. This friction imposes limits on efficient resource allocation. And these limits can be understood via a mechanism design problem which is novel in that there are no monetary transfers available. (If only the brain had currency.)
The optimal scheme has a quota structure which has some rigidity. There is a cap on the amount of resources a given division can utilize and that cap is determined solely by the needs of the other division. (This is a familiar theme from economic incentive mechanisms.) An implication is that there is too little flexibility in re-allocating resources to difficult tasks. Holding fixed the difficulty of task A, as the difficulty of task B increases, eventually the cap binds. The easy task is still accomplished perfectly but errors start to creep in on the difficult task.
(Drawing: Our team is non-hierarchical from www.f1me.net)
- A 60 Minutes interview of Sleeper-era Woody Allen. It’s interesting how little Woody Allen changed but how much 60 Minutes changed.
- McDonalds in France.
- Stuff an old guy googles.
I learned something from reading this article about a classic experimental finding in developmental psychology:
So you keep hiding the toy in “A” and the baby keeps searching for the toy in “A.” Simple enough. But what happens if you suddenly hide the toy in “B”? Remember, you’re hiding the toy in full view of the infant. An older child or an adult would simply reach for “B” to retrieve the toy. But not the infant. But, despite having just seen the object hidden in the new “B” location, infants between 8 and 12 months of age (the age at which infants begin to have enough motor control to successfully reach for an object) frequently look for it under box “A,” where it had previously been hidden. This effect, first demonstrated by Jean Piaget, is called the perseverative search error or sometimes the A-not-B error.
The result is robust to many variations on the experiment and the full article goes through some hypotheses about the error and a new experiment that turns them on their head.
So why are these the current “market probabilities” for American Idol?
- Lauren Alaina to be eliminated tonight: 50%
- Haley Reinhart to be eliminated tonight: 58%
- Scotty McReery to be eliminated tonight: 15%
The winning percentages also add up to more than 100. Is it not possible to short them all?
Thanks to Zeke for the pointer.
Apparently it’s biology and economics week for me because after Andrew Caplin finishes his fantastic series of lectures here at NU tomorrow, I am off to LA for this conference at USC on Biology, Neuroscience, and Economic Modeling.
Today Andrew was talking about the empirical foundations of dopamine as a reward system. Along the way he reminded us of an important finding about how dopamine actually works in the brain. It’s not what you would have guessed. If you take a monkey and do a Pavlovian experiment where you ring a bell and then later give him some goodies, the dopamine neurons fire not when the actual payoff comes, but instead when the bell rings. Interestingly, when you ring the bell and then don’t come through with the goods there is a dip in dopamine activity that seems to be associated with the letdown.
The theory is that dopamine responds to changes in expectations about payoffs, and not directly to the realization of those payoffs. This raises a very interesting theoretical question: why would that be Nature’s most convenient way to incentivize us? Think of Nature as the principal, you are the agent. You have decision-making authority because you know what choices are available and Nature gives you dopamine bonuses to guide you to good decisions. Can you come up with the right set of constraints on this moral hazard problem under which the optimal contract uses immediate rewards for the expectation of a good outcome rather than rewards that come later when the outcome actually obtains?
Here’s my lame first try, based on discount factors. Depending on your idiosyncratic circumstances your survival probability fluctuates, and this changes how much you discount the expectation of future rewards. Evolution can’t react to these changes. But if Nature is going to use future rewards to motivate your behavior today she is going to have to calibrate the magnitude of those incentive payments to your discount factor. The fluctuations in your discount factor make this prone to error. Immediate payments are better because they don’t require Nature to make any guesses about discounting.
Andrew Caplin is visiting Northwestern this week to give a series of lectures on psychology and economics. Today he talked about some of his early work and briefly mentioned an intriguing paper that he wrote with Kfir Eliaz.
Too few people get themselves tested for HIV infection. Probably this is because the anxiety that would accompany the bad news overwhelms the incentive to get tested in the hopes of getting the good news (and also the benefit of acting on whatever news comes out.) For many people, if they have HIV they would much rather not know it.
How do you encourage testing when fear is the barrier? Caplin and Eliaz offer one surprisingly simple, yet surely controversial possibility: make the tests less informative. But not just any old way. Because we want to maintain the carrot of a positive result but minimize the deterrent of a negative result. Now we could try outright deception by certifying everyone who tests negative but give no information to those who test positive. But that won’t fool people for long. Anyone who is not certified will know he is positive and we are back to the anxiety deterrent.
But even when we are bound by the constraint that subjects will not be fooled there is a lot of freedom to manipulate the informativeness of the test. Here’s how to ramp down the deterrent effect of bad result without losing much of the incentive effects of a good result. A patient who is tested will receive one of two outcomes: a certification that he is negative or an inconclusive result. The key idea is that when the patient is negative the test will be designed to produce an inconclusive result with positive probability p. (This could be achieved by actually degrading the quality of the test or just withholding the result with positive probability.)
Now a patient who receives an inconclusive result won’t be fooled. He will become more pessimistic, that is inevitable. But only slightly more pessimistic. The larger we choose p (the key policy instrument) the less scary is an inconclusive result. And no matter what p is, a certification that the patient is HIV-negative is a 100% certification. There is a tradeoff that arises, of course, and that is that high p means that we get the good news less often. But it should be clear that some p, often strictly between 0 and 1, would be optimal in the sense of maximizing testing and minimizing infection.
- There is an inverse relationship between how carefully you stack the dishes inside the dishwasher and how tidy you keep it outside in your kitchen.
- In addition to funny-haha and funny-strange there is a third category of joke where the impetus for laughter is that the comedian has made some embarrassing fact that is privately true for all of us into common knowledge.
- It would be too much of an accident for 50-50 genetic mixing to be evolutionarily optimal. So to compensate we must have a programmed taste either for mates who are similar to us or who are different.
- It is well known that in a moderately sized group of total strangers the probability is about 50% that two of them will have the same birthday. But when that group happens to be at a restaurant the probability is virtually 1.
I know of that line of apparel only because I have seen the name stenciled across the shirts and sweaters of its devotees. I infer that they are really nice clothes. Somehow I want to own some.
Which makes me wonder why they are not just giving their clothes away. We get free shirts, they get to drape their brand name across our bodies. Perhaps they would be selective about which bodies, but there must be a market opportunity here. If brand recognition drives sales then the eventual premium they could charge would seem to justify a lot of free hoodies up front. How else can we explain Abercrombie and Fitch, once a middling brand of fishing/hunting wear now international purveyors of pre-teen libido?
Normally this kind of rent seeking would be doubly inefficient. Resources wasted in a competition to corner the market, then the inefficient scarcity under the resulting monopoly. But in this case the rent seeking behavior involves giving away the stuff that’s eventually going to be so scarce. Moreover, since we apparently want to wear only the coolest clothes, the eventual monopoly may in fact be the first-best outcome. So we have firms competing to create the surplus maximizing market structure and in the process handing out all the accompanying rents in the form of euro-inscripted jeggings.
Here is a problem at has been in the back of my mind for a long time. What is the second best dominant-strategy mechanism (DSIC) in a market setting?
For some background, start with the bilateral trade problem of Myerson-Satterthwaite. We know that among all DSIC, budget-balanced mechanisms the most efficient is a fixed-price mechanism. That is, a price is fixed ex ante and the buyer and seller simply announce whether they are willing to trade at that price. Trade occurs if and only if both are willing and if so the buyer pays the fixed price to the seller. This is Hagerty and Rogerson.
Now suppose there are two buyers and two sellers. How would a fixed-price mechanism work? We fix a price p. Buyers announce their values and sellers announce their costs. We first see if there are any trades that can be made at the fixed price p. If both buyers have values above p and both sellers have values below then both units trade at price p. If two buyers have values above p and only one seller has value below p then one unit will be sold: the buyers will compete in a second-price auction and the seller will receive p (there will be a budget surplus here.) Similarly if the sellers are on the long side they will compete to sell with the buyer paying p and again a surplus.
A fixed-price mechanism is no longer optimal. The reason is that we can now use competition among buyers and sellers and “price discovery.” A simple mechanism (but not the optimal one) is a double auction. The buyers play a second-price auction between themselves, the sellers play a second-price reverse auction between themselves. The winner of the two auctions have won the right to trade. They will trade if and only if the second highest buyer value (which is what the winning buyer will pay) exceeds the second-lowest seller value (which is what the winning seller will receive.) This ensures that there will be no deficit. There might be a surplus, which would have to be burned.
This mechanism is DSIC and never runs a deficit. It is not optimal however because it only sells one unit. But it has the viture of allowing the “price” to adjust based on “supply and demand.” Still, there is no welfare ranking between this mechanism and a fixed-price mechanism because a fixed price mechanism will sometimes trade two units (if the price was chosen fortuitously) and sometimes trade no units (if the price turned out too high or low) even though the price discovery mechanism would have traded one.
But here is a mechanism that dominates both. It’s a hybrid of the two. We fix a price p and we interleave the rules of the fixed-price mechanism and the double auction in the following order
- First check if we can clear two trades at price p. If so, do it and we are done.
- If not, then check if we can sell one unit by the double auction rules. If so, do it and we are done.
- Finally, if no trades were executed using the previous two steps then return to the fixed-price and see if we can execute a single trade using it.
I believe this mechanism is DSIC (exercise for the reader, the order of execution is crucial!). It never runs a deficit and it generates more trade than either standalone mechanism: fixed-price or double auction.
Very interesting research question: is this a second-best mechanism? If not, what is? If so, how do you generalize it to markets with an arbitrary number of buyers and sellers?
- Poetry by selective transcription. (I think I will take one of her poems and add additional words to make a radio story.)
- Miley Cyrus singing Smells Like Teen Spirit.
- Expressionist urnial
- Re-assuring lack of correlation.
- This is just by way of public confession that I listened to this entire thing.
A buyer and a seller negotiating a sale price. The buyer has some privately known value and the seller has some privately known cost and with positive probability there are gains from trade but with positive probability the seller’s cost exceeds the buyers value. (So this is the Myerson-Satterthwaite setup.)
Do three treatments.
- The experimenter fixes a price in advance and the buyer and seller can only accept or reject that price. Trade occurs if and only if they both accept.
- The seller makes a take it or leave it offer.
- The parties can freely negotiate and they trade if and only if they agree on a price.
Theoretically there is no clear ranking of these three mechanisms in terms of their efficiency (the total gains from trade realized.) In practice the first mechanism clearly sacrifices some efficiency in return for simplicity and transparency. If the price is set right the first mechanism would outperform the second in terms of efficiency due to a basic market power effect. In principle the third treatment could allow the parties to find the most efficient mechanism, but it would also allow them to negotiate their way to something highly inefficient.
A conjecture would be that with a well-chosen price the first mechanism would be the most efficient in practice. That would be an interesting finding.
A variation would be to do something similar but in a public goods setting. We would again compare simple but rigid mechanisms with mechanisms that allow for more strategic behavior. For example, a version of mechanism #1 would be one in which each individual was asked to contribute an equal share of the cost and the project succeeds if and only if all agree to their contributions. Mechanism #3 would allow arbitrary negotation with the only requirement be that the total contribution exceeds the cost of the project.
In the public goods setting I would conjecture that the opposite force is at work. The scope for additional strategizing (seeding, cajoling, guilt-tripping, etc) would improve efficiency.
Anybody know if anything like these experiments have been done?

Its a recent development that economists are turning to neuroscience to inform and enrich economic theory. One controversial aspect is the potential use of neuroscience data to draw conclusions about welfare that go beyond traditional revealed preference. It is nicely summarized by this quote from Camerer, Lowenstein, and Prelec.
The foundations of economic theory were constructed assuming that details about the functioning of the brain’s black box would not be known. This pessimism was expressed by William Jevons in 1871:
I hesitate to say that men will ever have the means of measuring directly the feelings of the human heart. It is from the quantitative effects of the feelings that we must estimate their comparative amounts.
Since feelings were meant to predict behavior but could only be assessed from behavior, economists realized that, without direct measurement, feelings were useless intervening constructs. In the 1940s, the concepts of ordinal utility and revealed preference eliminated the superfluous inter- mediate step of positing immeasurable feelings. Revealed preference theory simply equates unobserved preferences with observed choices…
But now neuroscience has proved Jevons’s pessimistic prediction wrong; the study of the brain and nervous system is beginning to allow direct measurement of thoughts and feelings.
There are skeptics, I don’t count myself as one of them. I expect that we will learn from neuroscience and economics will benefit. But, I think it is helpful to explore the boundaries and I have a little thought experiment that I think sheds some light.
Imagine a neuroscientist emerges from his lab with a theory of what makes people happy. This theory is based on measuring activity in the brain and correlating it with measures of happiness and then repeated experiments studying how different activities affect happiness. For the purposes of this thought experiment be as generous as you wish to the neuroscientist, assume he has gone as far as you think is possible in measuring thoughts and feelings and their causes.
Now the neuroscientist approaches his first new patient and explains to him how to change his behavior in order to achieve the optimum level of well-being according to his theory, and asks the patient to give it a try. After a month of trying it out, imagine that the patient comes back and says “Doctor, I did everything you prescribed to the letter for one whole month. But, with all due respect, I would prefer to just go back to doing what I was doing before.”
Ask yourself if there is any circumstance, including any imaginable level of neuroscientific sophistication, under which after the patient tries and rejects the neuroscientist’s theory, you would accept a policy which over-rode the patient’s wishes and imposed upon him the lifestyle that the neuroscientist says is good for him.
If there is no circumstance then I claim you are fundamentally a revealed preference adherent. Because the example (again, I am asking you to be as charitable as you can be to the neuroscientist) presents the strongest possible case for including non-choice data into welfare considerations. We are allowing the patient to experience what the neuroscientist’s theory asserts to be his greatest possible state of well-being and even after experiencing that he is choosing not to experience it any more. If you insist that he has that freedom then you are deferring to his revealed preference over his “true” welfare.
That’s not to say that you must reject neuroscience as being valuable for welfare. Indeed it may be that when the patient goes his own way he does voluntarily incorporate some of what he learned. And so, even by a revealed preference standard could say that neuroscience has made him better off. But we can clearly bound its contribution. Neuroscience can make you better off only insofar as it can provide you with new information that you are free to use or reject as you prefer.
Drawing: Anxiety or Imagination from www.f1me.net
Kobe Bryant was recently fined $100,000 for making a homophobic comment to a referee. Ryan O’Hanlon writing for The Good Men Project blog puts it into perspective:
- It’s half as bad as conducting improper pre-draft workouts.
- It’s twice as bad as saying you want to leave the NBA and go home.
- It’s just as bad as talking about the collective bargaining agreement.
- It’s twice as bad as saying one of your players used to smoke too much weed.
- It’s just as bad as writing a letter in Comic Sans about a former player.
- It’s just as bad as saying you want to sign the best player in the NBA.
- It’s four times as bad as throwing a towel to distract a guy when he’s shooting free throws.
- It’s four times as bad as kicking a water bottle.
- It’s 10 times as bad as standing in front of your bench for an extended period of time.
- It’s 10 times as bad as pretending to be shot by a guy who once brought a gun into a locker room.
- It’s 13.33 times as bad as tweeting during a game.
- It’s five times as bad as throwing a ball into the stands.
- It’s four times as bad as throwing a towel into the stands.
- It’s twice as bad as lying about smelling like weed and having women in a hotel room during the rookie orientation program.
- It’s one-fifth as bad as snowboarding.
That’s based on a comparison of the fines that the various misdeeds earned. The “n times as bad” is the natural interpretation of the fines since we are used to thinking of penalties as being chosen to fit the crime. But NBA justice needn’t conform to our usual intuitions because this is an employer/employee relationship governed by actual contract, not just social contract. We could try to think of these fines as part of the solution to a moral hazard problem. Independent of how “bad” the behaviors are, there are some that the NBA wants to discourage and fines are chosen in order to get the incentives right.
But that’s a problematic interpretation too. From the moral hazard perspective the optimal fine for many of these would be infinite. Any finite fine is essentially a license to behave badly as long as the player has a strong enough desire to do so. Strong enough to outweigh the cost of the fine. You can’t throw a towel to distract a guy when he’s shooting free throws unless its so important to you that you are willing to pay $250,000 for the privilege.
You can rescue moral hazard as an explanation in some cases because if there is imperfect monitoring then the optimal fine will have to be finite. Because with imperfect monitoring the fine cannot be a perfect deterrent. For example it may not possible to detect with certainty that you were lying about smelling like weed and having women in a hotel room during the rookie orientation program. If so then the false positives will have to be penalized. And when the fine will be paid with positive probability even with players on their best behavior you are now trading off incentives vs. risk exposure.
But the imperfect monitoring story can’t explain why Comic Sans doesn’t get an infinite fine, purifying the game of that transgression once and for all. Or tweeting, or snowboarding or most of the others as well.

It could be that the NBA knows that egregious fines can be contested in court or trigger some other labor dispute. This would effectively put a cap on fines at just the level where it is not worth the player’s time and effort to dispute it. But that doesn’t explain why the fines are not all pegged at that cap. It could be that the likelihood that a fine of a given magnitude survives such a challenge depends on the public perception of the crime . That could explain some of the differences but not many. Why is the fine for saying you want to leave the NBA larger than the fine for throwing a ball into the stands?
Once we’ve dispensed with those theories it just might be that the NBA recognizes that players simply want to behave badly sometimes. Without that outlet something else is going to give. Poor performance perhaps or just an eventual Dennis Rodman. The NBA understands that a fine is a price. And with the players having so many ways of acting out to choose from, the NBA can use relative prices to steer them to the efficient frontier. Instead of kicking a water bottle, why not get your frustrations out by sending 3 1/2 tweets during the game? Instead of saying that one of your players smokes too much weed, go ahead and indulge your urge to stand out in front of the bench for an extended period of time. You can do it for 5 times as long as the last guy or even stand 5 times farther out.
Not surprisingly, all of these choices start to look like real bargains compared to snowboarding and impoper pre-draft workouts.
Nonsense?
For Shmanske, it’s all about defining what counts as 100% effort. Let’s say “100%” is the maximum amount of effort that can be consistently sustained. With this benchmark, it’s obviously possible to give less than 100%. But it’s also possible to give more. All you have to do is put forth an effort that can only be sustained inconsistently, for short periods of time. In other words, you’re overclocking.
And in fact, based on the numbers, NBA players pull greater-than-100-percent off relatively frequently, putting forth more effort in short bursts than they can keep up over a longer period. And giving greater than 100% can reduce your ability to subsequently and consistently give 100%. You overdraw your account, and don’t have anything left.
Here is the underlying paper. <Painfully repressing the theorist’s impulse to redefine the domain to paths of effort rather than flow efforts, thus restoring the spiritually correct meaning of 100%>
Cap curl: Tim Carmody guest blogging at kottke.org.
You can follow the list here, including Tom Hubbard, David Besanko, Eran Shmaya, and Josh Rauh. No Sandeep yet.

Or is it chronostasis?
Real luxury is now the ability to stop time. This week Luc Perramond, chief executive of Hermes’s watch division, presented the “temps suspendu” (suspended time) model, starting at 18,000 Swiss francs, which stops time at the press of a button and brings it back again.
For 240,000 Swiss francs you can pick up an Hublot watch whose time can be slowed or sped up and another which is all black, making it difficult to tell the time at all.
That luxury can set you back upwards of 15,000 Swiss francs.
“The value of a watch is not to give you time,” Hublot Chief Executive Jean-Claude Biver told Reuters.
“Any five dollar watch can do that. What we are offering is the ability for example to stop time or make it disappear… Time is a prison and people want to get out of it sometimes.”
In case you might still want to know whether it is day or night you can always wear this one on your other wrist.
(via Gizmodo)
There is a study by some economists and statisticans on the correlation between the price of a wine and ratings in blind tastings by tasters who are not informed of the price. The headline result in the paper is that higher priced wines don’t get higher ratings. If anything they get lower ratings. It is typically used in the first paragraph of blog posts to set up various theories about how people use price information to tell themselves what they should and shouldn’t like. (For example, here’s Jonah Lehrer.)
But why should we expect higher priced wine to get higher ratings in tastings? Suppose there are 100 different styles of wine and for every different style there is a group that likes that style and only that style. There will be a lot of variation in the price of different styles because the price will depend on the supply of that style and the size of the group that likes that style. Now ask a person to taste a randomly selected wine and rate it. There will be no correlation between price and ratings.
There are many styles of cheese with different prices. Would we expect the price of cheese to predict ratings in blind tastings?
Here’s another variation on the same idea. Suppose there are just two styles of wine, subtle and not-so-subtle. Some people appreciate the subtlety but most don’t. Suppose that the supply of subtle wine is lower so that its price is higher. Then again a study like this will produce an overall negative correlation between price and ratings.
And indeed if you read past page 3 of the paper you see that an effect like this is in the data.
Our data also indicates that experts, unlike non-experts, on average assign as high – or higher – ratings to more expensive wines. The coefficient on the expert*price interaction term is positive and highly statistically significant. The price coefficient for non-experts is negative, and about the same size as in the baseline model. The net coefficient on price for experts is the sum of these two coefficients. It is positive and marginally statistically significant.
The linear estimator offers an interpretation of these effects. In terms of a 100 point scale (such as that used by Wine Spectator), the extended model predicts that for a wine that costs ten times more than another wine, non-experts will on average assign an overall rating that is about four points lower, whereas experts will assign an overall rating that is about seven points higher.
The sources in this report say yes. These reporters look again and conclude no. I don’t believe any of them. The basic fact is that we have no good data on the costs and benefits of torture and we never will.
Once you have decided whether you or not you believe the practitioner/advocates of torture when they say that torture gets results then these stories contain no new information, and here’s why: all of the information comes from them. There is no independent source.
If you already believed that torture works then you came to that belief because they told you and today they are just telling you the same thing again. On the other hand, if you didn’t believe it that’s because you don’t trust them when they say it works and today you are just hearing another ex-post rationalization by people with dirty hands.
In tennis, a server should win a larger percentage of second-serve points compared to first-serve points; that much we know. Partly that’s because a server optimally serves more faults (serves that land out) on first serve than second serve. But what if we condition on the event that the first serve goes in? Here’s a flawed logic that takes a bit of thinking to see through:
Even conditional on a first serve going in, the probability that the server wins the point must be no larger than the total win probability for second serves. Because suppose it were larger. Then the server wins with a higher probability when his first serve goes in. So he should ease off just a bit on his first serve so that a larger percentage lands in, raising the total probability that he wins the point. Even though the slightly slower first serve wins with a slightly reduced probability (conditional on going in) he still has a net gain as long as he eases off just slightly so that it is still larger than the second serve percentage. Indeed the lower probability of a fault could even raise the total probability that he wins on the first serve.
The opening gambit of the book is surprisingly simple: If you were sentenced to five years in prison but had the option of receiving lashes instead, what would you choose? You would probably pick flogging. Wouldn’t we all?
I propose we give convicts the choice of the lash at the rate of two lashes per year of incarceration. One cannot reasonably argue that merely offering this choice is somehow cruel, especially when the status quo of incarceration remains an option. Prison means losing a part of your life and everything you care for. Compared with this, flogging is just a few very painful strokes on the backside. And it’s over in a few minutes. Often, and often very quickly, those who said flogging is too cruel to even consider suddenly say that flogging isn’t cruel enough. Personally, I believe that literally ripping skin from the human body is cruel. Even Singapore limits the lash to 24 strokes out of concern for the criminal’s survival. Now, flogging may be too harsh, or it may be too soft, but it really can’t be both.
The article is an excellent example of how considering an alternative (flogging replacing prison) which despite being non-serious still makes you think about the status quo in a new way.
If we could calibrate the number of lashes so as to create an equal disincentive but at a tiny fraction of the cost that should be a Pareto improvement right? Somehow that doesn’t seem right. I think the thought experiment reveals that one important part of incarceration is just to prevent the criminal from committing more crimes.
If N lashes is just as unpleasant as 1 year in prison what exactly does that mean? It says that N lashes plus whatever I decide to do during the next year is just as unpleasant as being shut in for a year. It will quite often be that the pivotal comparison is between prison and N lashes plus another year worth of crime. In that case we certainly don’t have a Pareto improvement.
(hoodhi: The Browser.)
You know the show Iron Chef? Someone should organize Iron Blogger. You are the chairman, you assemble your Iron Bloggers, and each week you invite a challenger blogger. The “secret ingredient” is a topic for the challenger and his chosen Iron Blogger to write about. You appoint judges to evaluate the writing according to content, style, and originality.

Seth Godin writes:
When two sides are negotiating over something that spoils forever if it doesn’t get shipped, there’s a straightforward way to increase the value of a settlement. Think of it as the net present value of a stream of football…
Any Sunday the NFL doesn’t play, the money is gone forever. You can’t make up for it later by selling more football–that money is gone. The owners don’t get it, the players don’t get it, the networks don’t get it, no one gets it.
The solution: While the lockout/strike/dispute is going on, keep playing. And put all the profit/pay in an escrow account. Week after week, the billions and billions of dollars pile up. The owners see it, the players see it, no one gets it until there’s a deal.
There are two questions you have to ask if you are going to evaluate this idea. First, what would happen if you change the rules in this way? Second, would the parties actually agree to it?
Bargaining theory is one of the most unsettled areas of game theory, but there is one very general and very robust principle. What drives the parties to agreement is the threat of burning surplus. Any time a settlement proposal on the table it comes with the following interpretation: “if you don’t agree to this now you better expect to be able to negotiate for a significantly larger share on the next round because between now and then a big chunk of the pie is going to disappear.” Moreover it is only through the willingness to let the pie shrink that either party can prove that he is prepared to make big sacrifices in order to get that larger share.
So while the escrow idea ensures that there will be plenty of surplus once they reach agreement, it has the paradoxical effect of making agreement even more difficult to reach. In the extreme it makes the timing of the agreement completely irrelevant. What’s the point of even negotiating today when we can just wait until tomorrow?
But of course who cares when and even whether they eventually agree? All we really want is to see football right? And even if they never agree how to split the mounting surplus, this protocol keeps the players on the field. True, but that’s why we have to ask whether the parties would actually accept this bargaining game. After all if we just wanted to force the players to play we wouldn’t have to get all cute with the rules of negotiation, we could just have an act of Congress.
And now we see why proposals like this can never really help because they just push the bargaining problem one step earlier, essentially just changing the terms of the negotiation without affecting the underlying incentives. As of today each party is looking ahead expecting some eventual payoff and some total surplus wasted. Godin’s rules of negotiation would mean that no surplus is wasted so that each party could expect an even higher eventual payoff. But if it were possible to get the two parties to agree to that then for exactly the same reason under the old-fashioned bargaining process there would be a proposal for immediate agreement with the same division of the spoils on the table today and inked tomorrow.
Still it is interesting from a theoretical point of view. It would make for a great game theory problem set to consider how different rules for dividing the accumulated profits would change the bargaining strategies. The mantra would be “Ricardian Equivalence.”
- Blackouts
- “Filling in the census, I realised there wasn’t much to report beyond the fact that I didn’t have a wife and ten children and I didn’t believe in the resurrected Christ.”
- Recidivist paint inhaling. (The mugshot is not to be missed.)
- Does he get fifth ammendment protection?
- Jihadville.
- Non-gay ringers on gay softball teams.
- Extreme ironing.
Now look, I am cool with “we” that means “one”, to celebrate the fact that the validity of mathematical statements is independent of the person who happens to claim them, as in “Dividing by
, we get that the game admits an equilibrium”. But sometimes the automatic replacement of `I’ with `we’ garbles the meaning of the sentence. When I write “I call such a sequence of variables a random play”, the singular pronoun implies that this is not a universally recognized definition, but one that I have invented for the current paper. Change this “I” to “we”, as the journal did, and the implication is lost. And sometimes `we’ for `one’ is just ridiculous, as in “We review Martin’s Theorem in the appendix”. It is one thing to say that every intelligent creature recognizes that the game admits an equilibrium, and another thing to say that every intelligent creature reviews Martin’s Theorem in the appendix.
Consider the following syllogism:
- If a person is an American, he is probably not a member of Congress.
- This person is a member of Congress.
- Therefore he is probably not American.
As John D. Cook writes:
We can’t reject a null hypothesis just because we’ve seen data that are rare under this hypothesis. Maybe our data are even more rare under the alternative. It is rare for an American to be in Congress, but it is even more rare for someone who is not American to be in the US Congress!
We often remember things by relying on the overall gist of an event—for example, instead of storing every detail about our last birthday, we tend to remember abstract things like “I had a fun party” or “I was in a grumpy mood because I felt old.” This strategy allows us to remember more things about an event, but there’s one major drawback: by storing memories based on gist, we actually change how we remember the event. This happens because we are biased to remember things that are consistent with our overall summary of the event. So if we remember the birthday party was “super fun” overall, we’ll exaggerate how we remember the details—the average chocolate cake is now “insanely good”, and the 10 friends who were there becomes a “huge crowd.” One of the factors that could contribute to this distortion is time; as you forget the details of an event, there’s more room for gist to change how you remember things. But you would remember the details of an event immediately afterward, right?
The article describes an experiment that suggests that this kind of classification-induced distortion occurs even for short-term memory.

Some of these things are coincidences, some not:
- The Bad Plus premeired their arrangement of Stravinsky’s Rite of Spring at Duke University on March 26, 2011.
- I happened to be at Duke University that day because the day before I presented “Torture” at the Economics Department.
- Atila Abdulkadiroglu and Bahar Leventoglu are my two favorite people in the whole world.
- After the show we met the band at a bar and had many drinks and fine conversation.
- Columbia B-School economist Maria Guadalupe was also there.
- Along with Philip Sadowski that brought the total number of economists enjoying free drinks on The Bad Plus to five.
- Maria’s sister is Cristina Guadalupe who collaborated on the visual arts aspect of the performance.
- Along with Philip’s wife that brought the total number of Spanish visual artists to two.
- Cristina is also married to the bass player Reid Anderson.
- And that is partly because Columbia B-school economist Bocachan Celen brought Maria to a Bad Plus performance and somehow this led to Reid meeting Cristina.
- Ethan Iverson does not want a MacArthur Fellowship.
- You can hear a recording of that night’s performance of The Rite of Spring here.
If I had to describe my feeling about the performance that night then I would probably procrastinate by doing something else because that’s how I tend to respond when I have to do something. If I didn’t have to then I would say that it was a night I will never forget.
Drawing: Spring from www.f1me.net

{kind=link}